
Arthur Schnitzler
Weiterlesen →
Arthur Schnitzler gehört zu den bedeutendsten österreichischen Autoren und war ein produktiver und gut vernetzter Briefschreiber. Seine Korrespondenz wurde jedoch
Arthur Schnitzler gehört zu den bedeutendsten österreichischen Autoren und war ein produktiver und gut vernetzter Briefschreiber. Seine Korrespondenz wurde jedoch

Annotieren, Analysieren, Interpretieren und Visualisieren: In CATMA können Textwissenschaftler:innen so arbeiten, wie es ihren Fragestellungen am besten entspricht: qualitativ oder

Das forTEXT Portal bietet einsteigerfreundlich aufbereitete, zitierfähige Methodenbeschreibungen und Reviews von Textsammlungen und Tools – von Digitalisierung über Annotation zu

Das Institut für Dokumentologie und Editorik e.V. (IDE) ist ein internationaler Zusammenschluss von Wissenschaftlerinnen und Wissenschaftlern aus verschiedenen Disziplinen der
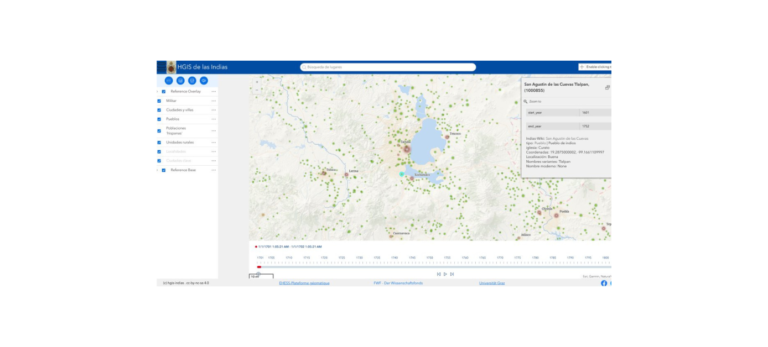
HGIS de las Indias ist eine historisch-geographische Datenbank zum Spanisch-Amerika der ausgehenden Kolonialzeit.
Arthur Schnitzler gehört zu den bedeutendsten österreichischen Autoren und war ein produktiver und gut vernetzter Briefschreiber. Seine Korrespondenz wurde jedoch
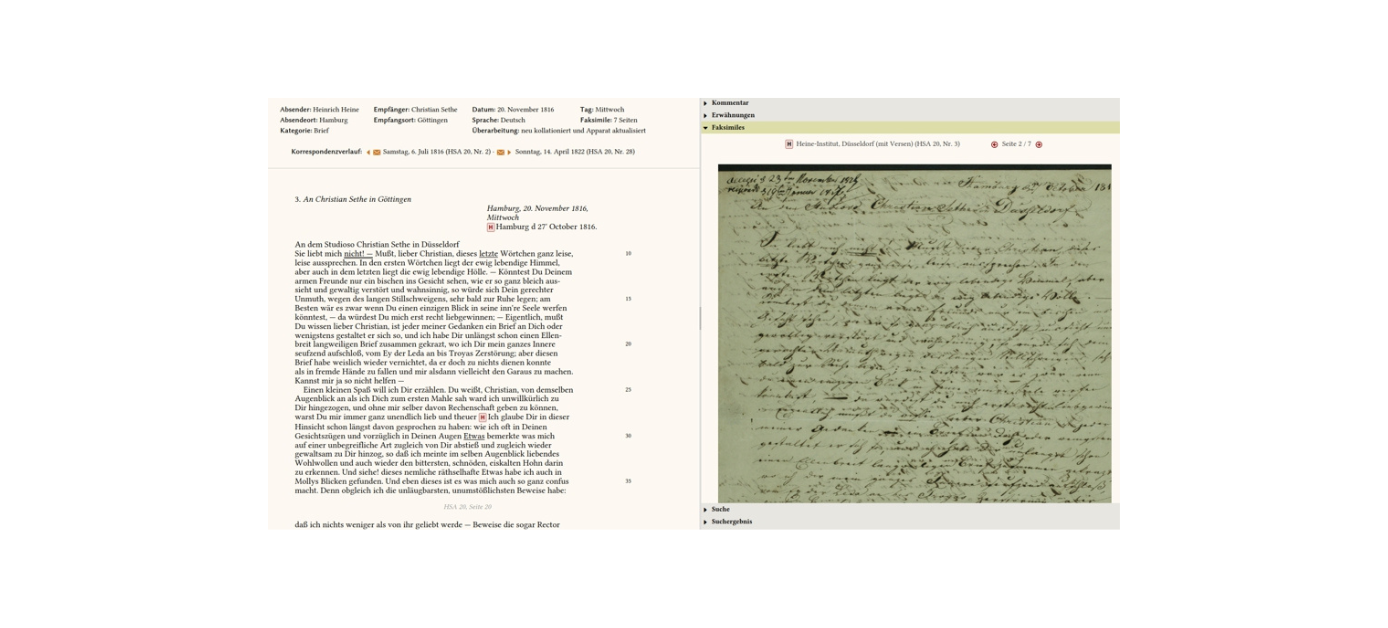
Das Heinrich-Heine-Portal schöpft aus den Arbeitsergebnissen mehrerer Forschergenerationen, indem es die beiden historisch-kritischen Heine-Gesamtausgaben, die unabhängig voneinander in der Bundesrepublik und der DDR entstanden, in einer digitalen Edition vereint.

Mit Dietrich online werden bibliographische Angaben zu ca. 5. Mio im deutschen Sprachraum von 1897- 1944 erschienenen Zeitschriftenaufsätzen und Zeitungsartikeln in einer nach Autorennamen, Titelstichwörtern, deutschsprachigen Schlagwörtern, Zeitschriften- resp. Zeitungstiteln und Jahren durchsuchbaren Online-Datenbank nachgewiesen.