
HZSK
Weiterlesen →
Das Hamburger Zentrum für Sprachkorpora berät und unterstützt bei der Erstellung und Nutzung digitaler Sprachkorpora in Forschung und Lehre: Es
Das Hamburger Zentrum für Sprachkorpora berät und unterstützt bei der Erstellung und Nutzung digitaler Sprachkorpora in Forschung und Lehre: Es
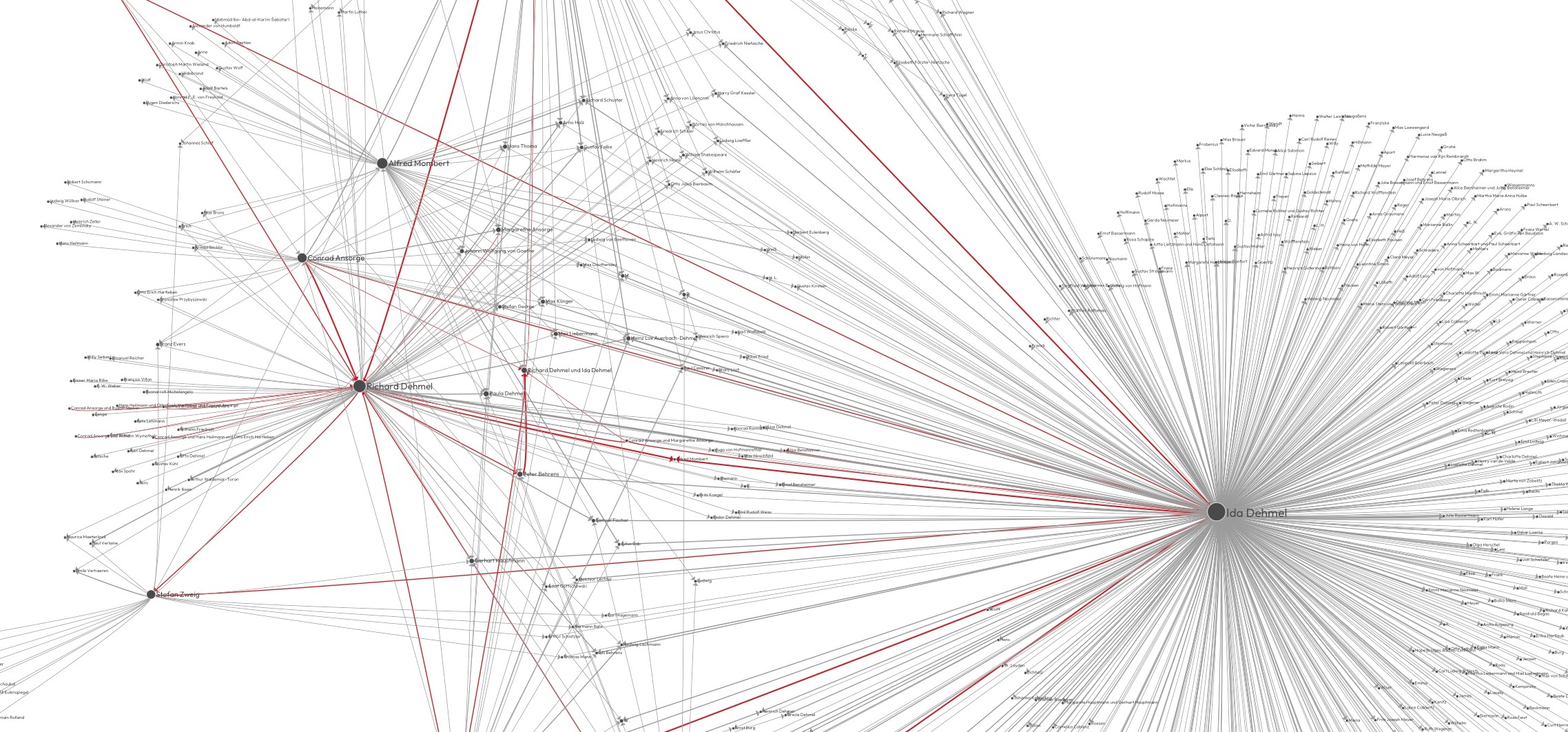
In Kooperation zwischen der Universität Hamburg und der Staats- und Universitätsbibliothek Hamburg werden die ca. 35.000 handschriftlichen Originalbriefe des Dehmel-Archivs

In einem langfristigen Kooperationsprojekt von Österreichischer Nationalbibliothek und Deutschem Literaturarchiv Marbach werden alle bis 1990 entstandenen 75 Notizbücher in einer

DisKo steht für Diversitäts-Korpus und ist ein literaturwissenschaftliches Projekt mit Digital-Humanities-Komponente. Mit Methoden des maschinellen Lernens wollen wir einen Algorithmus

Die digitale Arbeitsumgebung ediarum ist eine aus mehreren Softwarekomponenten bestehende Lösung, die es Wissenschaftler*innen erlaubt, Transkriptionen von Manuskripten und Drucken

Annotieren, Analysieren, Interpretieren und Visualisieren: In CATMA können Textwissenschaftler:innen so arbeiten, wie es ihren Fragestellungen am besten entspricht: qualitativ oder

In einem langfristigen Kooperationsprojekt von Österreichischer Nationalbibliothek und Deutschem Literaturarchiv Marbach werden alle bis 1990 entstandenen 75 Notizbücher in einer kommentierten digitalen Edition erstmals veröffentlicht und frei zugänglich gemacht.

Das von der Deutschen Forschungsgemeinschaft geförderte Projekt Diccionario del Español Medieval electrónico (DEMel) hat zum Ziel, der Öffentlichkeit ein lemmatisiertes