
Längsschnittstudie
Weiterlesen →
Nachhaltiges Forschungsdatenmanagement ist zentral für künftige Forschungen! Dies zeigt etwa die Geschichte der Bonner Längsschnittstudie des Alterns. Fast zwanzig Jahre
Nachhaltiges Forschungsdatenmanagement ist zentral für künftige Forschungen! Dies zeigt etwa die Geschichte der Bonner Längsschnittstudie des Alterns. Fast zwanzig Jahre

Das von der NRW Akademie der Wissenschaften und der Künste sowie der Union der Deutschen Akademien finanzierte Langzeitprojekt an der
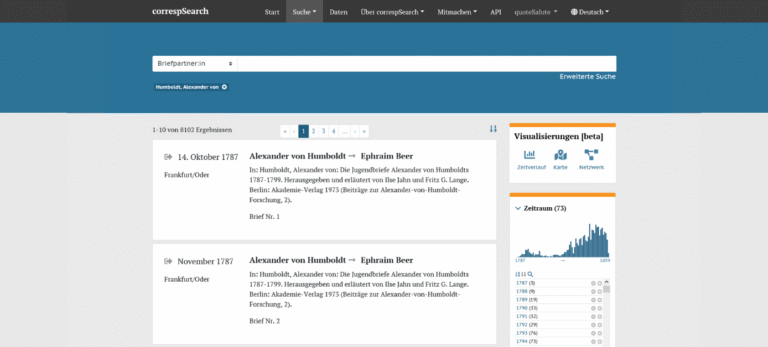
Der Webservice correspSearch wurde entwickelt um ein lange bestehendes Desiderat von Briefeditionen zu beheben: Die edierten Briefe editionsübergreifend durchsuchen zu

Die Virtuelle Forschungsumgebung TextGrid ist optimiert für die digitale Erschließung geisteswissenschaftlicher Quellen und deren langfristige Archivierung in einem Web-Archiv, insbesondere

Im Zentrum steht die Erforschung digitaler, datenintensiver Medien, die sich auf breiter Front als kooperative Werkzeuge, Plattformen und Infrastrukturen herausgestellt

is in die 1990er Jahre war es in der Filmwissenschaft ein Gemeinplatz, dass Frauen in den Anfangsjahren der Filmproduktion nur
is in die 1990er Jahre war es in der Filmwissenschaft ein Gemeinplatz, dass Frauen in den Anfangsjahren der Filmproduktion nur

Das Hamburger Zentrum für Sprachkorpora berät und unterstützt bei der Erstellung und Nutzung digitaler Sprachkorpora in Forschung und Lehre: Es versteht sich als Kompetenzzentrum, das technische, methodische und organisatorische Expertise für die Arbeit mit Sprachkorpora aufbaut und bündelt.