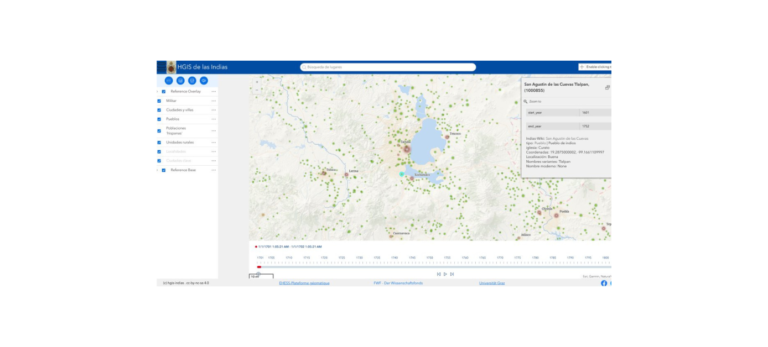
HGIS de las Indias
Weiterlesen →
HGIS de las Indias ist eine historisch-geographische Datenbank zum Spanisch-Amerika der ausgehenden Kolonialzeit.
HGIS de las Indias ist eine historisch-geographische Datenbank zum Spanisch-Amerika der ausgehenden Kolonialzeit.
Das Projekt erarbeitet eine Neuedition der fränkischen Herrschererlasse („Kapitularien”), die zu den zentralen Rechtsquellen des europäischen Mittelalters gehören. Zum einen

Der Vergleich als methodisches und epistemologisches Paradigma ist in den Geisteswissenschaften tief verankert. Ob in der qualitativen oder quantitativen Forschung

Das Zusammenwirken von über 1,200 Projektbeteiligten aus über 50 Ländern ermöglicht eine umfassende Darstellung der „Urkatastrophe des 20. Jahrhunderts“ in

Die Website „Der Holocaust in Ungarn und die Deportationen nach Norddeutschland“ präsentiert Ergebnisse aus dem transnationalen Projekt „Digitale Gedenk- und
Das Portal Revistas culturales 2.0 dient als virtuelle Forschungsumgebung für alle Interessenten, die sich mit historischen Zeitschriften aus dem spanischsprachigen
Die digitale Ausgabe der Werke Friedrichs des Großen der Universitätsbibliothek Trier bietet eine XML-konforme und recherchierbare elektronische Volltextversion der von Johann David Erdmann Preuß zwischen 1846 und 1856 herausgegeben Werkausgabe sowie der von Reinhold Koser begründeten Ausgabe der Politischen Correspondenz Friedrichs des Großen der Jahre 1740-1782.
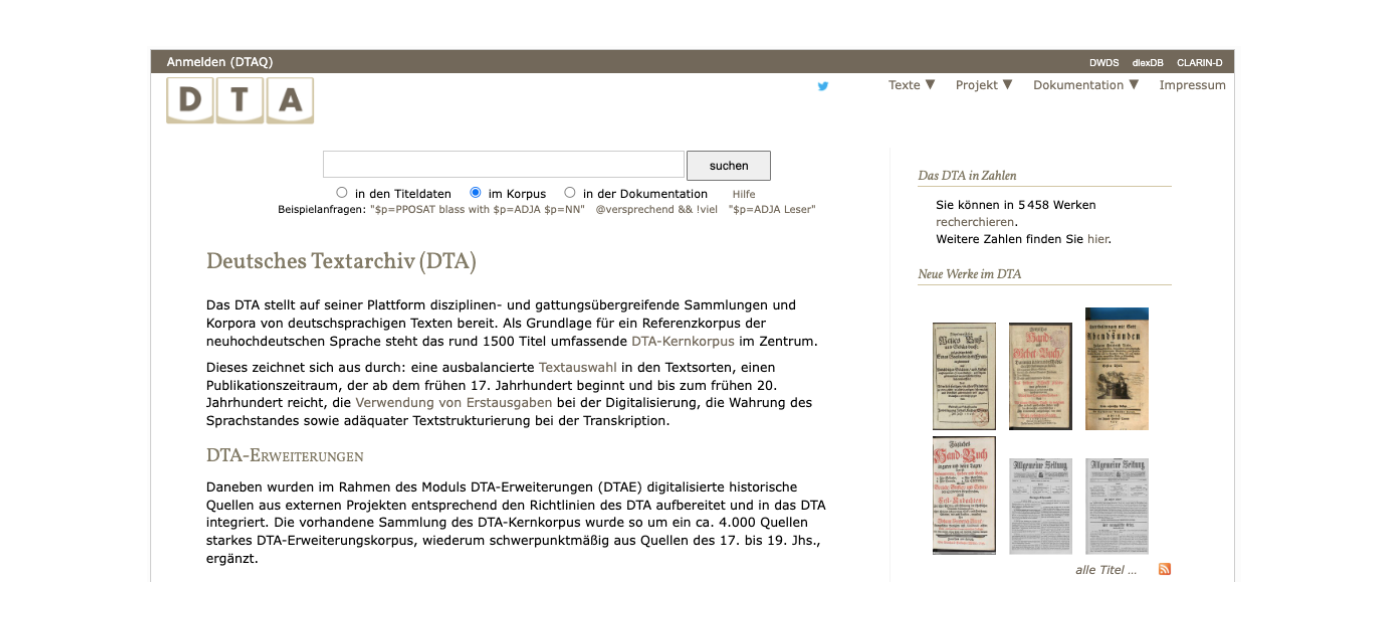
Das DTA ist ein Archiv für deutschsprachige, historische Textsammlungen an der Berlin-Brandenburgischen Akademie der Wissenschaften. Es umfasst annotierte Volltexttranskriptionen von Drucken, Zeitungen, Zeitschriften sowie handgeschriebene Dokumente verschiedener Gattungen und Textarten. Für die Transkriptionen steht mit dem DTABf ein etabliertes Basisformat zur Verfügung.