
Projekt DisKo
Weiterlesen →
DisKo steht für Diversitäts-Korpus und ist ein literaturwissenschaftliches Projekt mit Digital-Humanities-Komponente. Mit Methoden des maschinellen Lernens wollen wir einen Algorithmus
DisKo steht für Diversitäts-Korpus und ist ein literaturwissenschaftliches Projekt mit Digital-Humanities-Komponente. Mit Methoden des maschinellen Lernens wollen wir einen Algorithmus

Annotieren, Analysieren, Interpretieren und Visualisieren: In CATMA können Textwissenschaftler:innen so arbeiten, wie es ihren Fragestellungen am besten entspricht: qualitativ oder
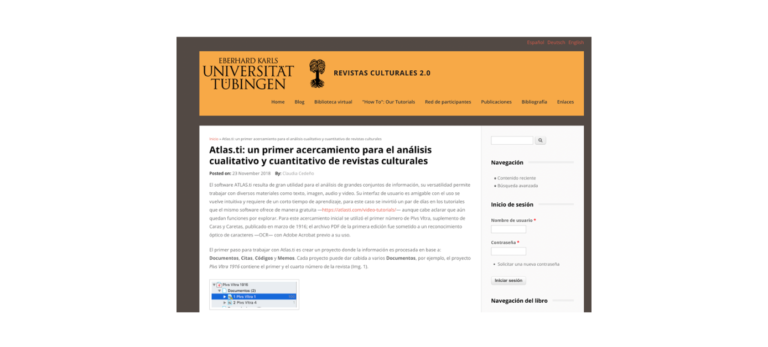
Das Portal Revistas culturales 2.0 dient als virtuelle Forschungsumgebung für alle Interessenten, die sich mit historischen Zeitschriften aus dem spanischsprachigen

Das Institut für Dokumentologie und Editorik e.V. (IDE) ist ein internationaler Zusammenschluss von Wissenschaftlerinnen und Wissenschaftlern aus verschiedenen Disziplinen der

Die im aschkenasischen Europa und Norditalien verbreiteten Pinkasim – Protokollbücher jüdischer Gemeinden – sind zentrale Quellen zur Erforschung der jüdischen

Das von der NRW Akademie der Wissenschaften und der Künste sowie der Union der Deutschen Akademien finanzierte Langzeitprojekt an der
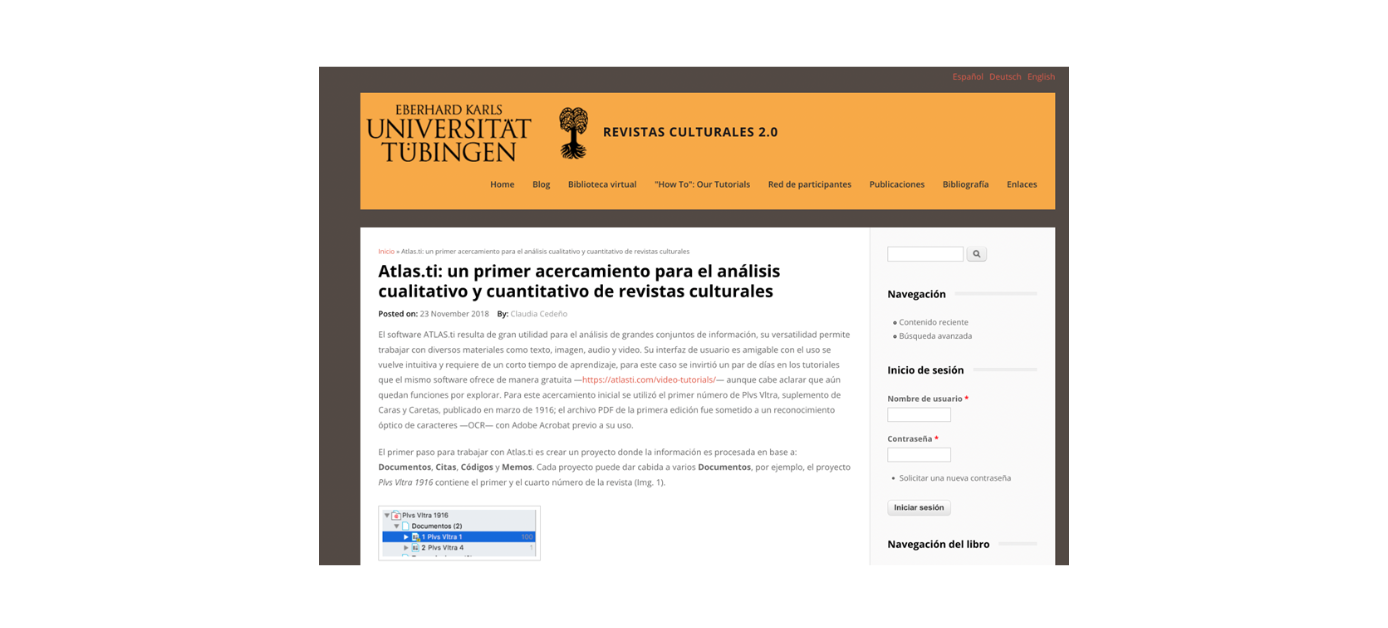
Das Portal Revistas culturales 2.0 dient als virtuelle Forschungsumgebung für alle Interessenten, die sich mit historischen Zeitschriften aus dem spanischsprachigen Kulturkreis beschäftigen.

Digitale Ausgabe der 1773 bis 1858 in 242 Bänden erschienenen Oekonomisch-technologischen Enzyklopädie von J. G. Krünitz.