
HZSK
Weiterlesen →
Das Hamburger Zentrum für Sprachkorpora berät und unterstützt bei der Erstellung und Nutzung digitaler Sprachkorpora in Forschung und Lehre: Es
Das Hamburger Zentrum für Sprachkorpora berät und unterstützt bei der Erstellung und Nutzung digitaler Sprachkorpora in Forschung und Lehre: Es
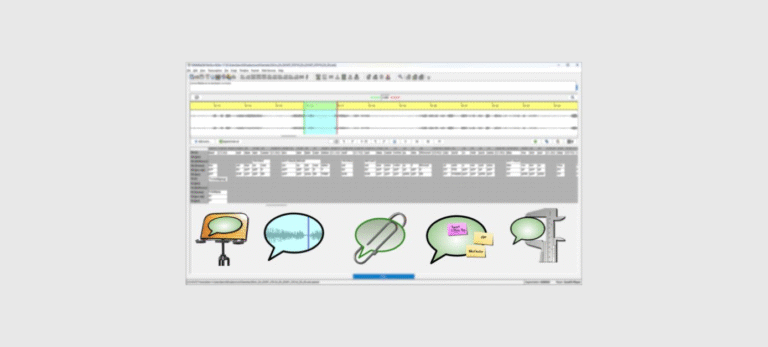
EXMARaLDA wurde ursprünglich (2000-2011) am SFB Mehrsprachigkeit der Universität Hamburg entwickelt. Die Entwicklung von FOLKER und OrthoNormal wurde über das

Das forTEXT Portal bietet einsteigerfreundlich aufbereitete, zitierfähige Methodenbeschreibungen und Reviews von Textsammlungen und Tools – von Digitalisierung über Annotation zu

Im Zentrum steht die Erforschung digitaler, datenintensiver Medien, die sich auf breiter Front als kooperative Werkzeuge, Plattformen und Infrastrukturen herausgestellt

Der Vergleich als methodisches und epistemologisches Paradigma ist in den Geisteswissenschaften tief verankert. Ob in der qualitativen oder quantitativen Forschung

Der DARIAH-DE Geo-Browser ermöglicht eine vergleichende Visualisierung mehrerer Anfragen und unterstützt die Darstellung von Daten und deren Visualisierung in einer

Der Vergleich als methodisches und epistemologisches Paradigma ist in den Geisteswissenschaften tief verankert. Ob in der qualitativen oder quantitativen Forschung
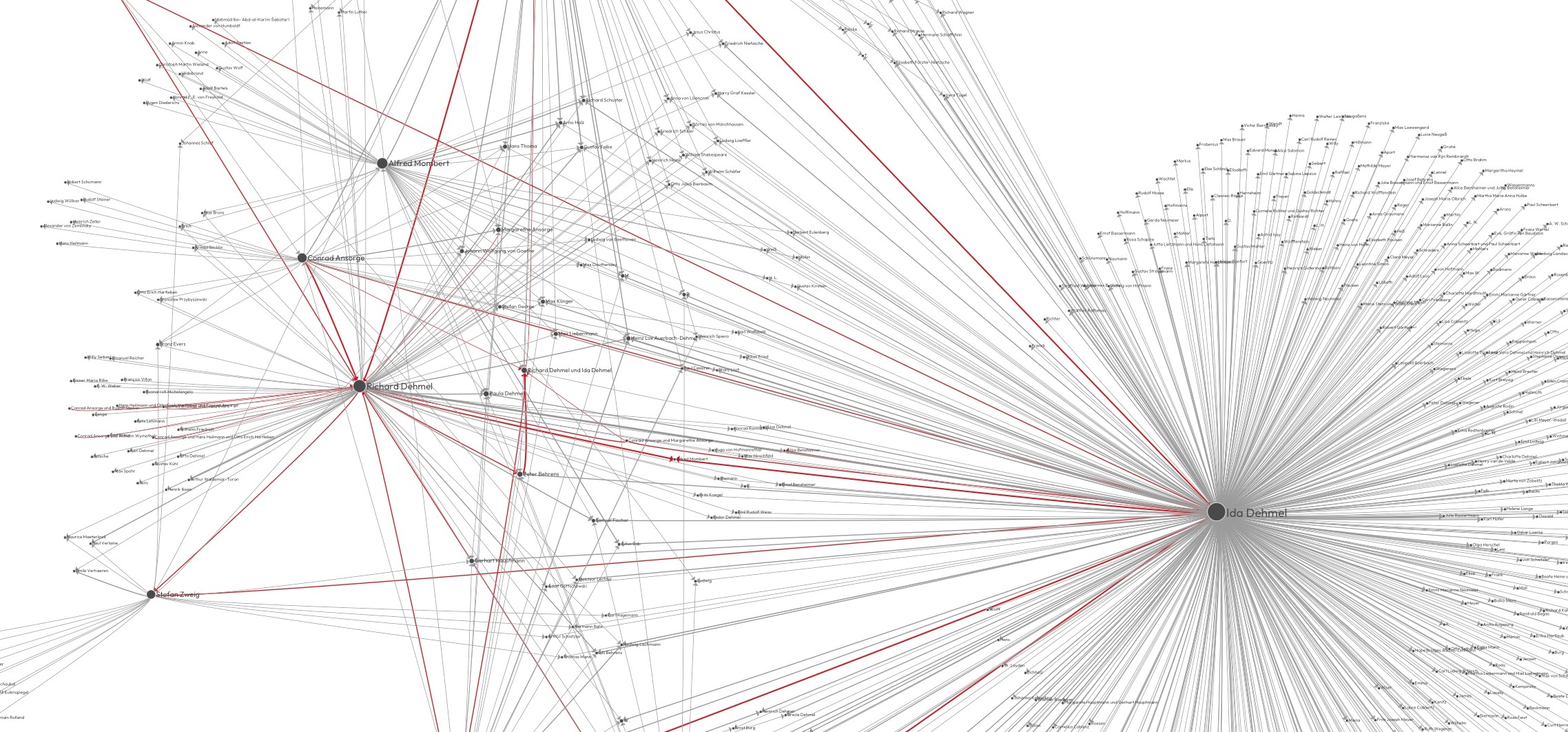
In Kooperation zwischen der Universität Hamburg und der Staats- und Universitätsbibliothek Hamburg werden die ca. 35.000 handschriftlichen Originalbriefe des Dehmel-Archivs