
DARIAH-DE Geo-Browser
Weiterlesen →
Der DARIAH-DE Geo-Browser ermöglicht eine vergleichende Visualisierung mehrerer Anfragen und unterstützt die Darstellung von Daten und deren Visualisierung in einer
Der DARIAH-DE Geo-Browser ermöglicht eine vergleichende Visualisierung mehrerer Anfragen und unterstützt die Darstellung von Daten und deren Visualisierung in einer

Arthur Schnitzler gehört zu den bedeutendsten österreichischen Autoren und war ein produktiver und gut vernetzter Briefschreiber. Seine Korrespondenz wurde jedoch

Die im aschkenasischen Europa und Norditalien verbreiteten Pinkasim – Protokollbücher jüdischer Gemeinden – sind zentrale Quellen zur Erforschung der jüdischen

Das MultiHTR-Team setzt die Ergebnisse der ersten erfolgreichen Projektphase (01. Juni 2020 bis 31. Mai 2022) fort, um in der
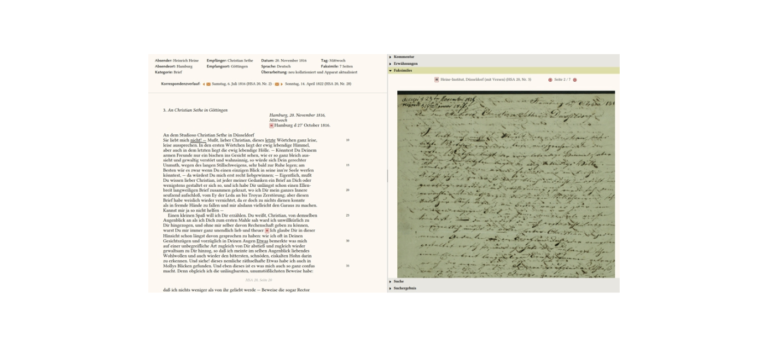
Das Heinrich-Heine-Portal schöpft aus den Arbeitsergebnissen mehrerer Forschergenerationen, indem es die beiden historisch-kritischen Heine-Gesamtausgaben, die unabhängig voneinander in der Bundesrepublik

Nachhaltiges Forschungsdatenmanagement ist zentral für künftige Forschungen! Dies zeigt etwa die Geschichte der Bonner Längsschnittstudie des Alterns. Fast zwanzig Jahre
Das Institut für Dokumentologie und Editorik e.V. (IDE) ist ein internationaler Zusammenschluss von Wissenschaftlerinnen und Wissenschaftlern aus verschiedenen Disziplinen der Geisteswissenschaften, die sich den Digital Humanities zugehörig fühlen.

Digitale Ausgabe der 1773 bis 1858 in 242 Bänden erschienenen Oekonomisch-technologischen Enzyklopädie von J. G. Krünitz.