
TextGrid
Weiterlesen →
Die Virtuelle Forschungsumgebung TextGrid ist optimiert für die digitale Erschließung geisteswissenschaftlicher Quellen und deren langfristige Archivierung in einem Web-Archiv, insbesondere
Die Virtuelle Forschungsumgebung TextGrid ist optimiert für die digitale Erschließung geisteswissenschaftlicher Quellen und deren langfristige Archivierung in einem Web-Archiv, insbesondere

Annotieren, Analysieren, Interpretieren und Visualisieren: In CATMA können Textwissenschaftler:innen so arbeiten, wie es ihren Fragestellungen am besten entspricht: qualitativ oder

Das Ziel der Bibliotheca legum ist es, einen Überblick über die handschriftliche Produktion weltlichen Rechts in der Karolingerzeit zu geben.

Die im aschkenasischen Europa und Norditalien verbreiteten Pinkasim – Protokollbücher jüdischer Gemeinden – sind zentrale Quellen zur Erforschung der jüdischen
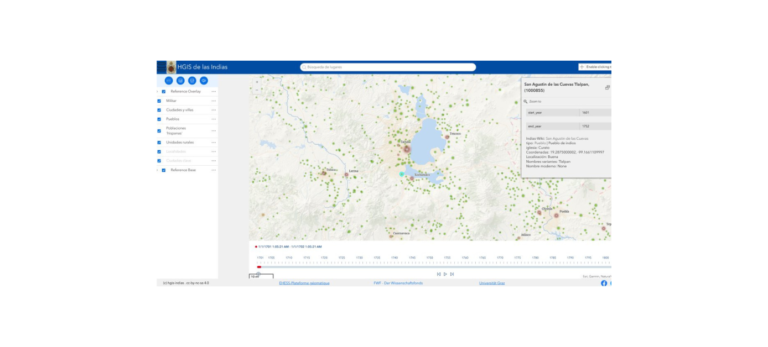
HGIS de las Indias ist eine historisch-geographische Datenbank zum Spanisch-Amerika der ausgehenden Kolonialzeit.
Das Ziel der Bibliotheca legum ist es, einen Überblick über die handschriftliche Produktion weltlichen Rechts in der Karolingerzeit zu geben.

CLARIAH-DE ist ein Beitrag zur digitalen Forschungsinfrastruktur für die Geisteswissenschaften und benachbarte Disziplinen. Durch die Zusammenführung der Verbünde CLARIN-D und
Das Institut für Dokumentologie und Editorik e.V. (IDE) ist ein internationaler Zusammenschluss von Wissenschaftlerinnen und Wissenschaftlern aus verschiedenen Disziplinen der Geisteswissenschaften, die sich den Digital Humanities zugehörig fühlen.