
„Lesen heißt diese Übung“ – und dann?
Weiterlesen →
Das Projekt untersucht den öffentlich-schriftlichen Diskurs der Literaturvermittlung an höheren Schulen im 19. Jahrhundert für alle deutschen Staaten – außer
Das Projekt untersucht den öffentlich-schriftlichen Diskurs der Literaturvermittlung an höheren Schulen im 19. Jahrhundert für alle deutschen Staaten – außer

GAMS ist ein OAIS-konformes Repositorium zur Verwaltung, Publikation und Langzeitarchivierung digitaler Ressourcen aus allen geisteswissenschaftlichen Fächern.
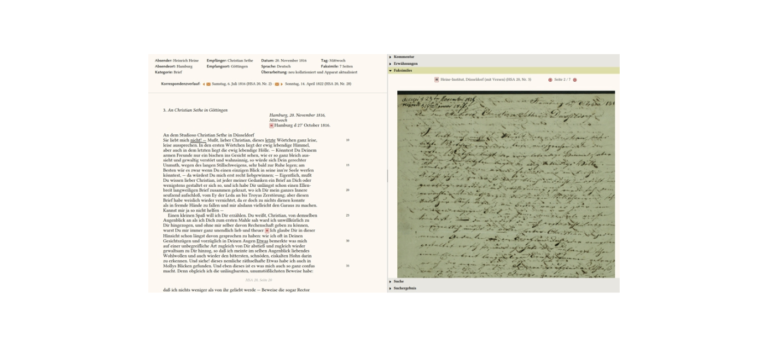
Das Heinrich-Heine-Portal schöpft aus den Arbeitsergebnissen mehrerer Forschergenerationen, indem es die beiden historisch-kritischen Heine-Gesamtausgaben, die unabhängig voneinander in der Bundesrepublik
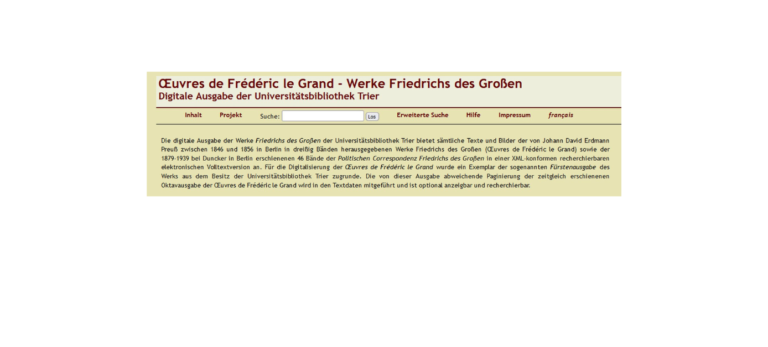
Die digitale Ausgabe der Werke Friedrichs des Großen der Universitätsbibliothek Trier bietet eine XML-konforme und recherchierbare elektronische Volltextversion der von

In einem langfristigen Kooperationsprojekt von Österreichischer Nationalbibliothek und Deutschem Literaturarchiv Marbach werden alle bis 1990 entstandenen 75 Notizbücher in einer

Das Forschungs- und Lehrkorpus Gesprochenes Deutsch (FOLK) wird seit 2008 am Leibniz-Institut für Deutsche Sprache aufgebaut. Das Korpus enthält Audio-
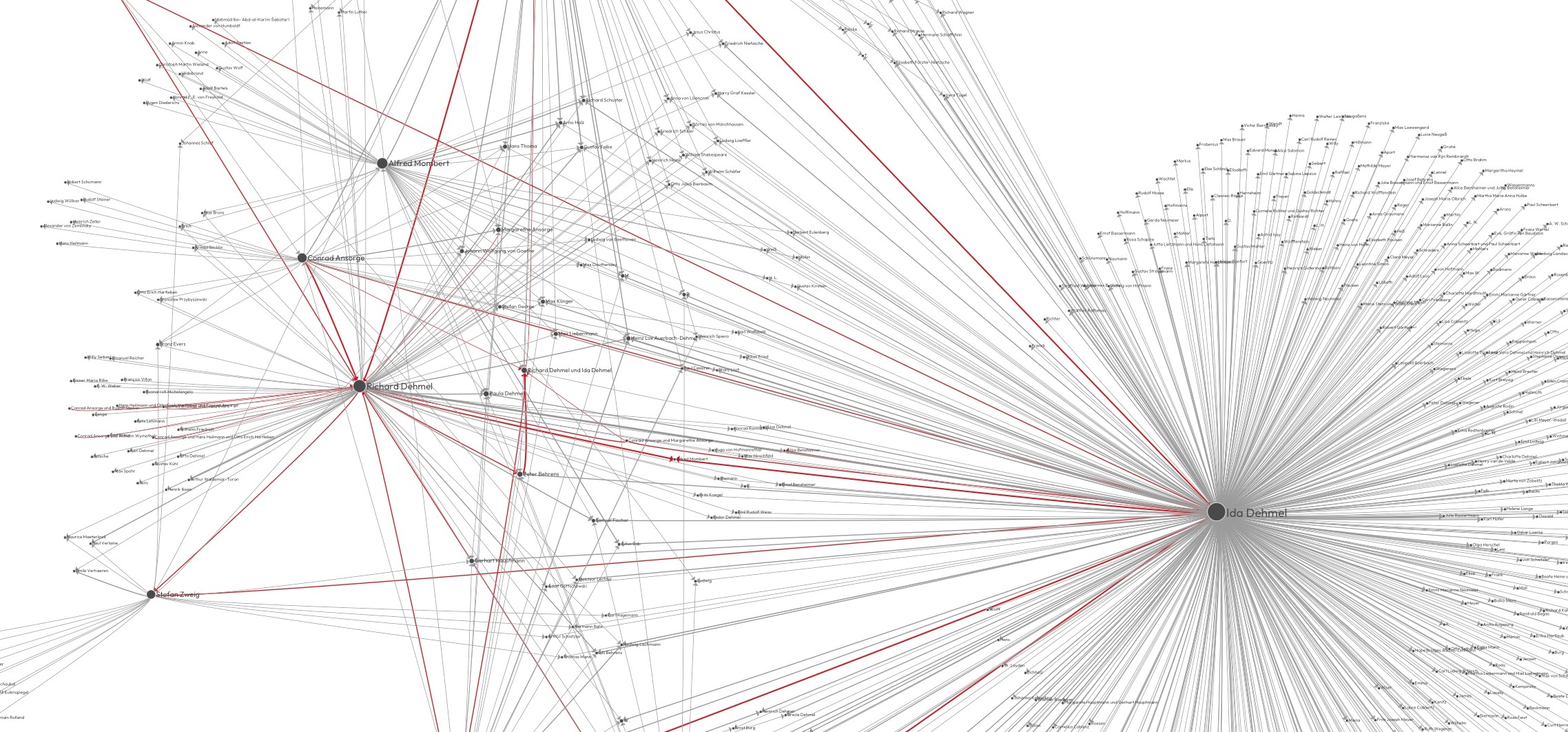
In Kooperation zwischen der Universität Hamburg und der Staats- und Universitätsbibliothek Hamburg werden die ca. 35.000 handschriftlichen Originalbriefe des Dehmel-Archivs

Das von der Deutschen Forschungsgemeinschaft geförderte Projekt Diccionario del Español Medieval electrónico (DEMel) hat zum Ziel, der Öffentlichkeit ein lemmatisiertes