
Auden Musulin Papers
Weiterlesen →
Von 1958 bis 1973 lebte und arbeitete der anglo-amerikanische Dichter Wystan Hugh Auden (1907-1973) viele Monate im Jahr im niederösterreichischen
Von 1958 bis 1973 lebte und arbeitete der anglo-amerikanische Dichter Wystan Hugh Auden (1907-1973) viele Monate im Jahr im niederösterreichischen
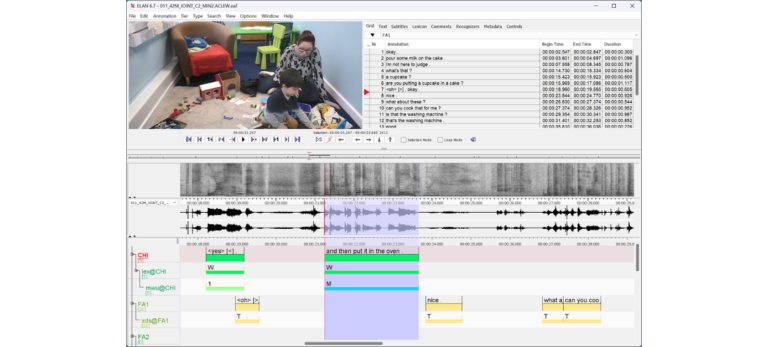
ELAN wird am Max-Planck-Institut für Psycholinguistik im Sprach-Archiv (TLA – The Language Archive) entwickelt. Es wird in der Programmiersprache Java
Das von der Deutschen Forschungsgemeinschaft geförderte Projekt Diccionario del Español Medieval electrónico (DEMel) hat zum Ziel, der Öffentlichkeit ein lemmatisiertes

Das von der NRW Akademie der Wissenschaften und der Künste sowie der Union der Deutschen Akademien finanzierte Langzeitprojekt an der

CLARIAH-DE ist ein Beitrag zur digitalen Forschungsinfrastruktur für die Geisteswissenschaften und benachbarte Disziplinen. Durch die Zusammenführung der Verbünde CLARIN-D und

Die Virtuelle Forschungsumgebung TextGrid ist optimiert für die digitale Erschließung geisteswissenschaftlicher Quellen und deren langfristige Archivierung in einem Web-Archiv, insbesondere

DisKo steht für Diversitäts-Korpus und ist ein literaturwissenschaftliches Projekt mit Digital-Humanities-Komponente. Mit Methoden des maschinellen Lernens wollen wir einen Algorithmus

is in die 1990er Jahre war es in der Filmwissenschaft ein Gemeinplatz, dass Frauen in den Anfangsjahren der Filmproduktion nur