
1914-1918-online
Weiterlesen →
Das Zusammenwirken von über 1,200 Projektbeteiligten aus über 50 Ländern ermöglicht eine umfassende Darstellung der „Urkatastrophe des 20. Jahrhunderts“ in
Das Zusammenwirken von über 1,200 Projektbeteiligten aus über 50 Ländern ermöglicht eine umfassende Darstellung der „Urkatastrophe des 20. Jahrhunderts“ in
Das Projekt erarbeitet eine Neuedition der fränkischen Herrschererlasse („Kapitularien”), die zu den zentralen Rechtsquellen des europäischen Mittelalters gehören. Zum einen

Annotieren, Analysieren, Interpretieren und Visualisieren: In CATMA können Textwissenschaftler:innen so arbeiten, wie es ihren Fragestellungen am besten entspricht: qualitativ oder
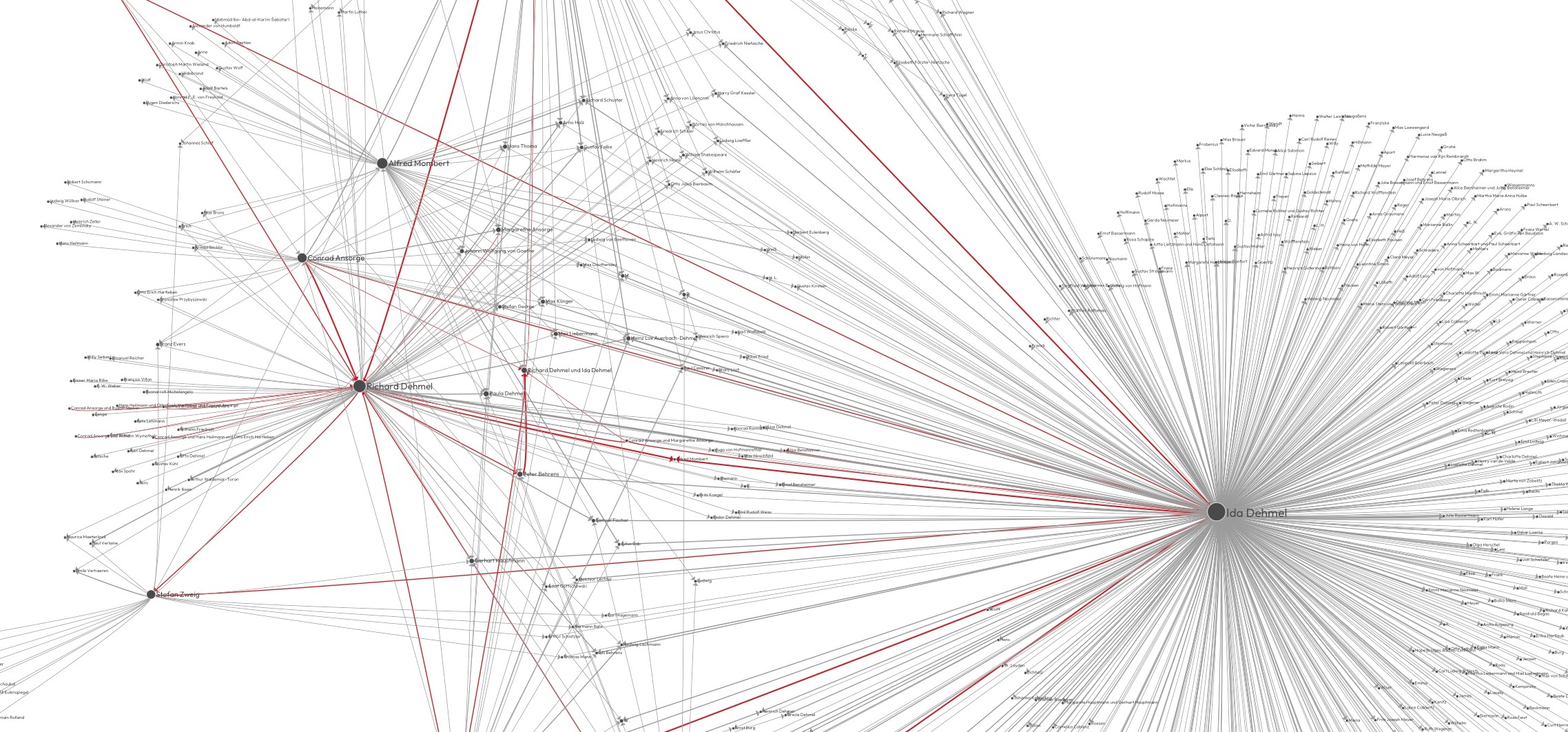
In Kooperation zwischen der Universität Hamburg und der Staats- und Universitätsbibliothek Hamburg werden die ca. 35.000 handschriftlichen Originalbriefe des Dehmel-Archivs

Das von der NRW Akademie der Wissenschaften und der Künste sowie der Union der Deutschen Akademien finanzierte Langzeitprojekt an der
Die Edition „Hamburger Schlüsseldokumente zur deutsch-jüdischen Geschichte“ soll sowohl einem akademischen Publikum als auch der interessierten Öffentlichkeit einen niedrigschwelligen Zugang

DARIAH-DE (gefördert 2011-2019) unterstützt die mit digitalen Ressourcen und Methoden arbeitenden Geistes- und Kulturwissenschaftler/innen in Forschung und Lehre. Dazu baut der Verbund eine digitale Forschungsinfrastruktur auf und entwickelt Materialien für Lehre und Weiterbildung im Bereich der Digital Humanities (DH). Die DARIAH-DE Betriebskooperation (2019-2021) setzt diese Ziele fort.
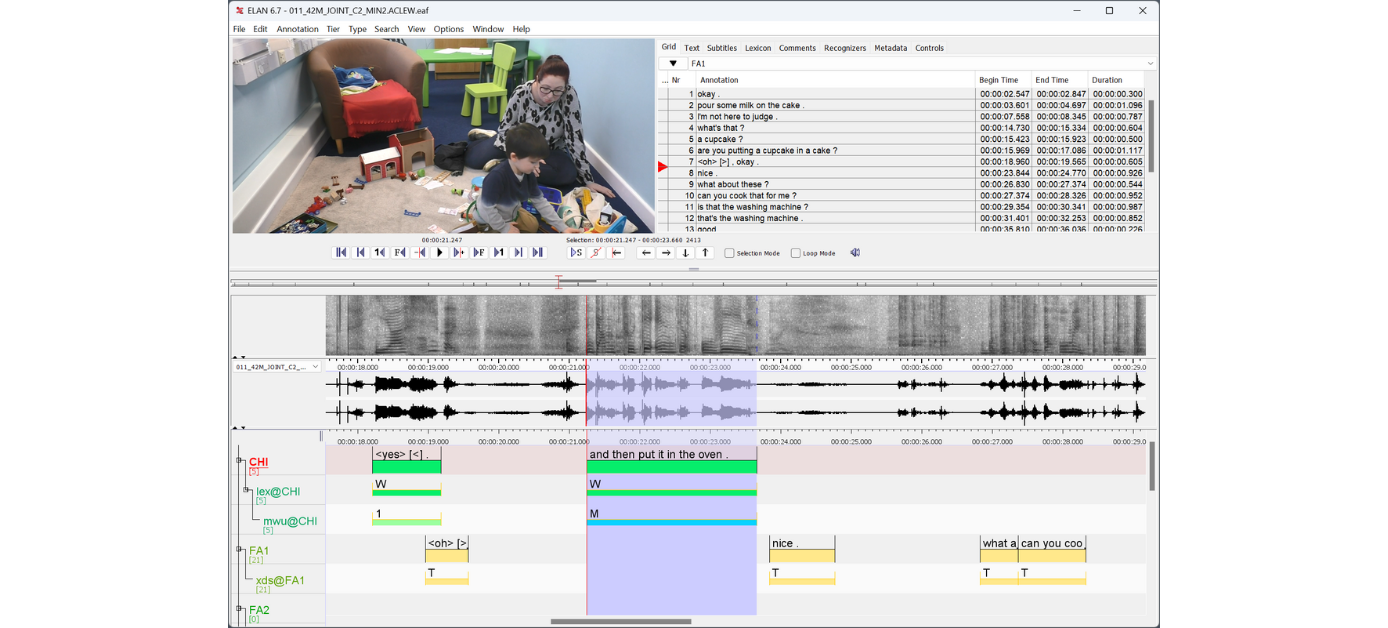
ELAN wird am Max-Planck-Institut für Psycholinguistik im Sprach-Archiv (TLA – The Language Archive) entwickelt. Es wird in der Programmiersprache Java geschrieben, die Quellen sind erhältlich für non-kommerzielle und kommerzielle Zwecken.