
CATMA
Weiterlesen →
Annotieren, Analysieren, Interpretieren und Visualisieren: In CATMA können Textwissenschaftler:innen so arbeiten, wie es ihren Fragestellungen am besten entspricht: qualitativ oder
Annotieren, Analysieren, Interpretieren und Visualisieren: In CATMA können Textwissenschaftler:innen so arbeiten, wie es ihren Fragestellungen am besten entspricht: qualitativ oder
Das Projekt erarbeitet eine Neuedition der fränkischen Herrschererlasse („Kapitularien”), die zu den zentralen Rechtsquellen des europäischen Mittelalters gehören. Zum einen

Die digitale Arbeitsumgebung ediarum ist eine aus mehreren Softwarekomponenten bestehende Lösung, die es Wissenschaftler*innen erlaubt, Transkriptionen von Manuskripten und Drucken

DisKo steht für Diversitäts-Korpus und ist ein literaturwissenschaftliches Projekt mit Digital-Humanities-Komponente. Mit Methoden des maschinellen Lernens wollen wir einen Algorithmus

Im Zentrum steht die Erforschung digitaler, datenintensiver Medien, die sich auf breiter Front als kooperative Werkzeuge, Plattformen und Infrastrukturen herausgestellt
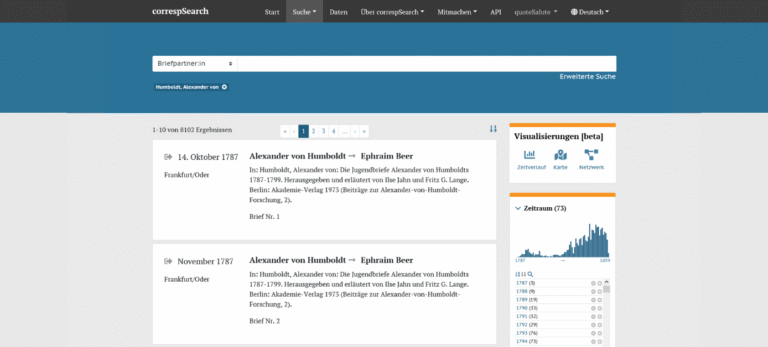
Der Webservice correspSearch wurde entwickelt um ein lange bestehendes Desiderat von Briefeditionen zu beheben: Die edierten Briefe editionsübergreifend durchsuchen zu

Die Virtuelle Forschungsumgebung TextGrid ist optimiert für die digitale Erschließung geisteswissenschaftlicher Quellen und deren langfristige Archivierung in einem Web-Archiv, insbesondere von TEI-codierten Ressourcen

Das Ziel der Bibliotheca legum ist es, einen Überblick über die handschriftliche Produktion weltlichen Rechts in der Karolingerzeit zu geben. Die Bibliotheca präsentiert Beschreibungen (nach TEI P5) aller Handschriften, die weltliche Rechtstexte (leges) enthalten sowie weitere kontextualisierende Materialien.