
Hidden Kosmos
Weiterlesen →
Das Hidden Kosmos – Reconstructing Alexander von Humboldt’s »Kosmos-Lectures« widmete sich von 2014–16 der Ermittlung und Verzeichnung, Bild- und Volltext-Digitalisierung
Das Hidden Kosmos – Reconstructing Alexander von Humboldt’s »Kosmos-Lectures« widmete sich von 2014–16 der Ermittlung und Verzeichnung, Bild- und Volltext-Digitalisierung
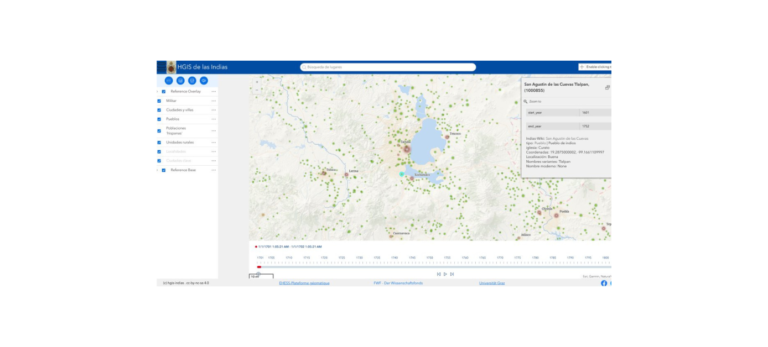
HGIS de las Indias ist eine historisch-geographische Datenbank zum Spanisch-Amerika der ausgehenden Kolonialzeit.
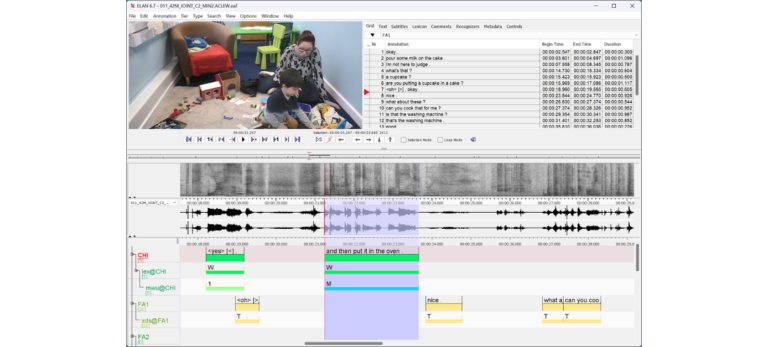
ELAN wird am Max-Planck-Institut für Psycholinguistik im Sprach-Archiv (TLA – The Language Archive) entwickelt. Es wird in der Programmiersprache Java

DisKo steht für Diversitäts-Korpus und ist ein literaturwissenschaftliches Projekt mit Digital-Humanities-Komponente. Mit Methoden des maschinellen Lernens wollen wir einen Algorithmus

Die Website schafft einen schnellen und unkomplizierten Zugang zu den Werkmaterialien des österreichischen Literaturnobelpreisträgers Peter Handke.

Arthur Schnitzler gehört zu den bedeutendsten österreichischen Autoren und war ein produktiver und gut vernetzter Briefschreiber. Seine Korrespondenz wurde jedoch
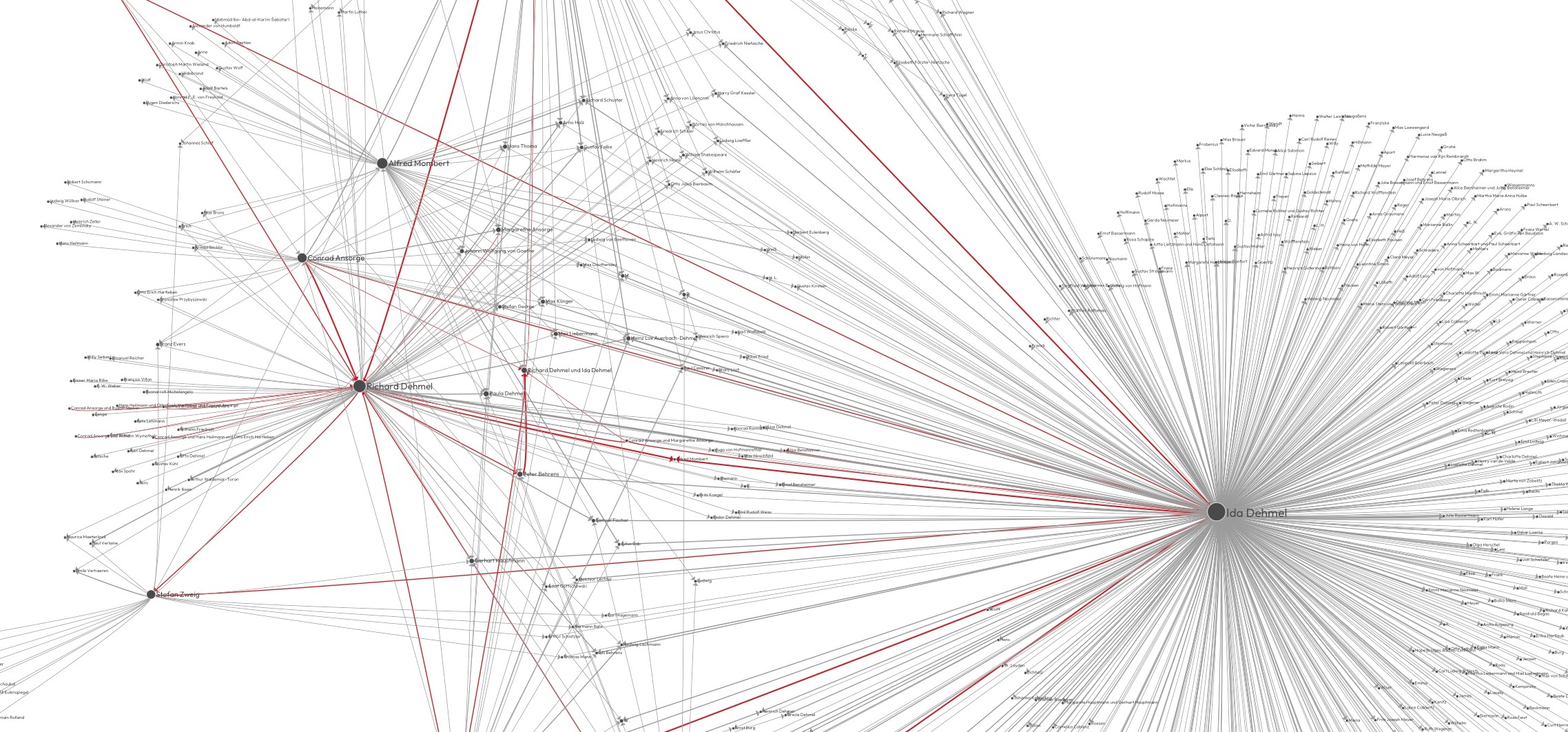
In Kooperation zwischen der Universität Hamburg und der Staats- und Universitätsbibliothek Hamburg werden die ca. 35.000 handschriftlichen Originalbriefe des Dehmel-Archivs

The Trier dictionary network offers access to more than 40 dictionaries and reference works, which can either be called up individually or queried together using a comprehensive search. At the same time, the dictionaries are interlinked at keyword level so that iterative navigation within the dictionary network is possible.