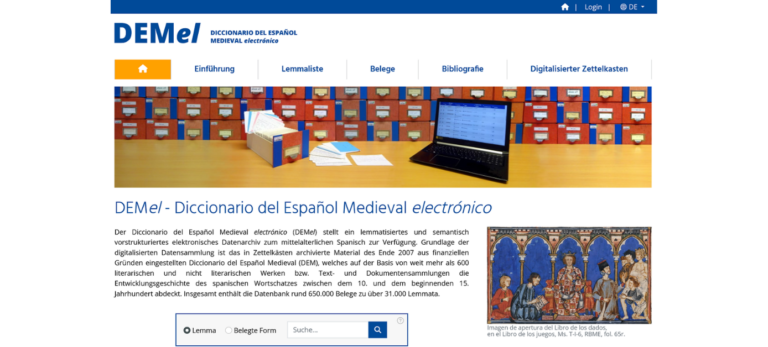
DEMel
Weiterlesen →
Das von der Deutschen Forschungsgemeinschaft geförderte Projekt Diccionario del Español Medieval electrónico (DEMel) hat zum Ziel, der Öffentlichkeit ein lemmatisiertes
Das von der Deutschen Forschungsgemeinschaft geförderte Projekt Diccionario del Español Medieval electrónico (DEMel) hat zum Ziel, der Öffentlichkeit ein lemmatisiertes

Das Institut für Dokumentologie und Editorik e.V. (IDE) ist ein internationaler Zusammenschluss von Wissenschaftlerinnen und Wissenschaftlern aus verschiedenen Disziplinen der
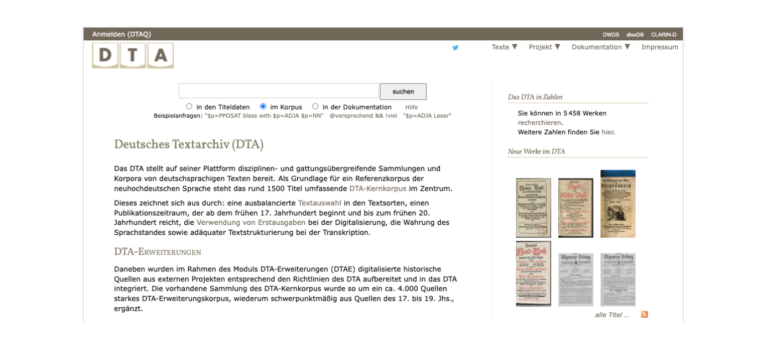
Das DTA ist ein Archiv für deutschsprachige, historische Textsammlungen an der Berlin-Brandenburgischen Akademie der Wissenschaften. Es umfasst annotierte Volltexttranskriptionen von
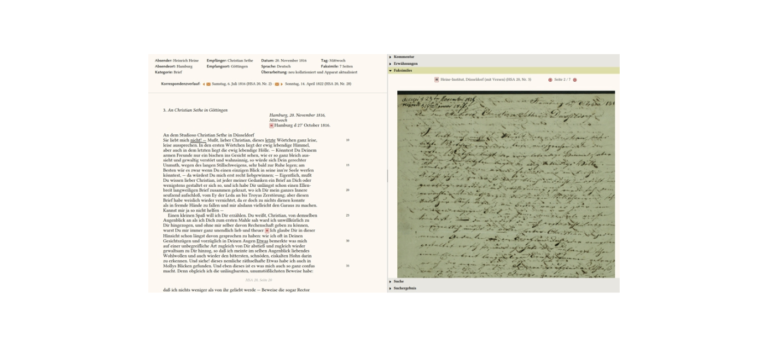
Das Heinrich-Heine-Portal schöpft aus den Arbeitsergebnissen mehrerer Forschergenerationen, indem es die beiden historisch-kritischen Heine-Gesamtausgaben, die unabhängig voneinander in der Bundesrepublik
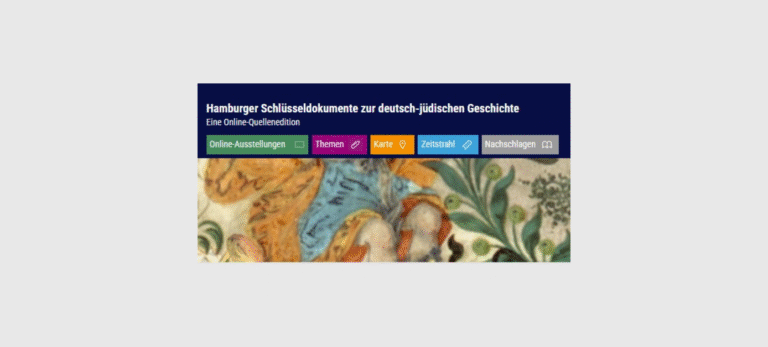
Die Edition „Hamburger Schlüsseldokumente zur deutsch-jüdischen Geschichte“ soll sowohl einem akademischen Publikum als auch der interessierten Öffentlichkeit einen niedrigschwelligen Zugang

Nachhaltiges Forschungsdatenmanagement ist zentral für künftige Forschungen! Dies zeigt etwa die Geschichte der Bonner Längsschnittstudie des Alterns. Fast zwanzig Jahre

Das MultiHTR-Team setzt die Ergebnisse der ersten erfolgreichen Projektphase (01. Juni 2020 bis 31. Mai 2022) fort, um in der

The DARIAH-DE Geo-Browser enables a comparative visualization of several queries and supports the display of data and their visualization in a correlation of geographical spatial relationships at corresponding points in time and sequences. This allows researchers to analyze space-time relations of data and source collections and at the same time establish correlations between them.