
Wörterbuchnetz
Weiterlesen →
Das Trierer Wörterbuchnetz bietet Zugriff auf mehr als 40 Wörterbücher und Nachschlagewerke, die entweder einzeln aufgerufen oder mittels einer übergreifenden
Das Trierer Wörterbuchnetz bietet Zugriff auf mehr als 40 Wörterbücher und Nachschlagewerke, die entweder einzeln aufgerufen oder mittels einer übergreifenden

Die digitale Arbeitsumgebung ediarum ist eine aus mehreren Softwarekomponenten bestehende Lösung, die es Wissenschaftler*innen erlaubt, Transkriptionen von Manuskripten und Drucken

ZenMEM ist ein dezidiert offener Verbund von Wissenschaftler*innen und darum bemüht, gemeinsam neue, digital gestützte Forschungsmöglichkeiten im Bereich der Kulturwissenschaften

Die drei von Text+ adressierten Datendomänen Sammlungen, lexikalische Ressourcen und Editionen gehören zu den klassischen Feldern geisteswissenschaftlicher Forschung. Das Plus-Zeichen
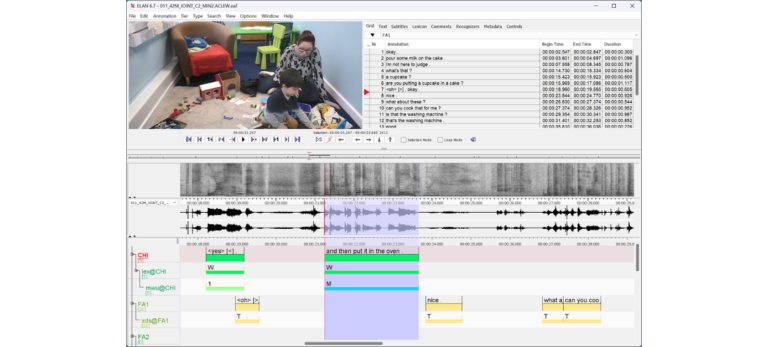
ELAN wird am Max-Planck-Institut für Psycholinguistik im Sprach-Archiv (TLA – The Language Archive) entwickelt. Es wird in der Programmiersprache Java
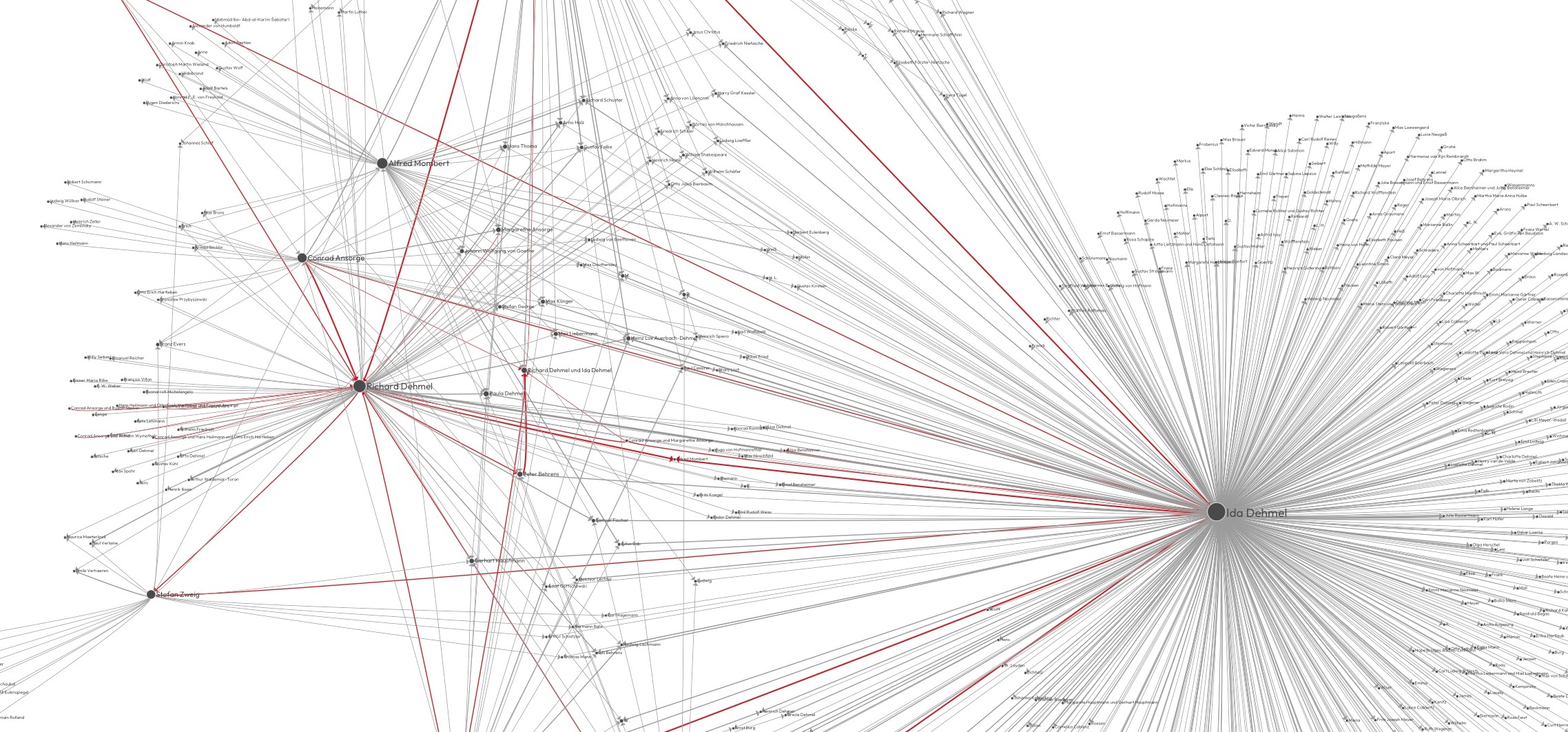
In Kooperation zwischen der Universität Hamburg und der Staats- und Universitätsbibliothek Hamburg werden die ca. 35.000 handschriftlichen Originalbriefe des Dehmel-Archivs
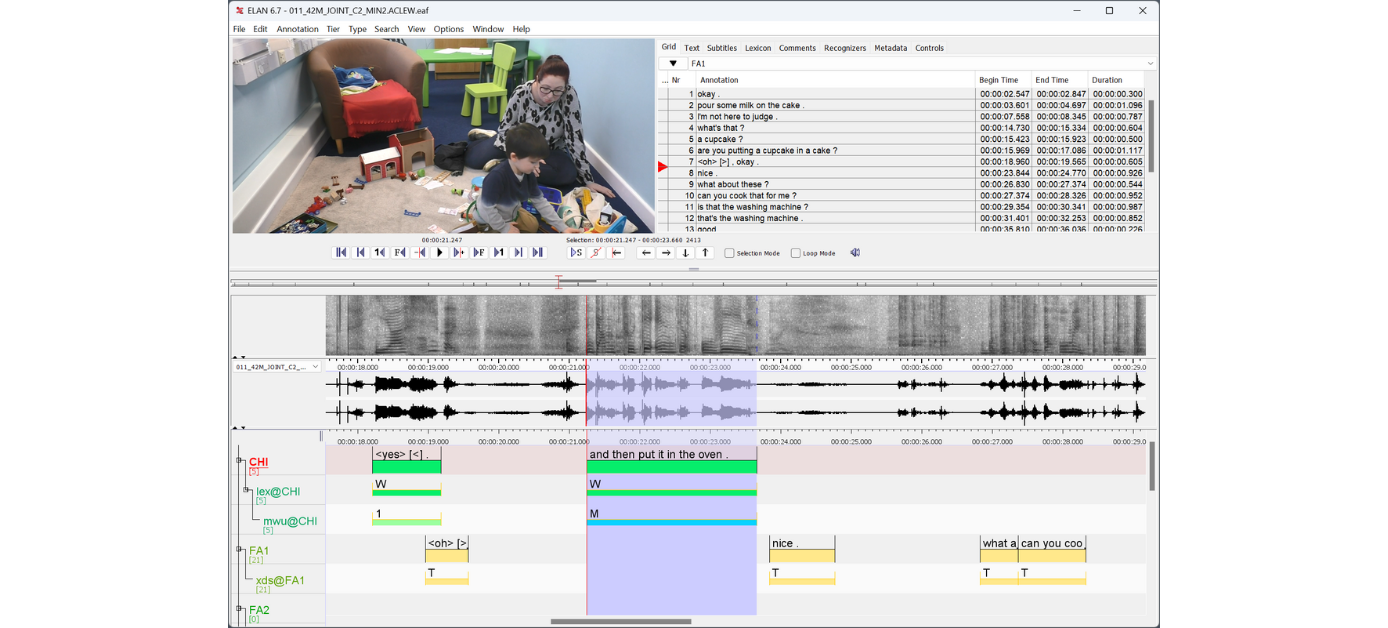
ELAN wird am Max-Planck-Institut für Psycholinguistik im Sprach-Archiv (TLA – The Language Archive) entwickelt. Es wird in der Programmiersprache Java geschrieben, die Quellen sind erhältlich für non-kommerzielle und kommerzielle Zwecken.

In einem langfristigen Kooperationsprojekt von Österreichischer Nationalbibliothek und Deutschem Literaturarchiv Marbach werden alle bis 1990 entstandenen 75 Notizbücher in einer kommentierten digitalen Edition erstmals veröffentlicht und frei zugänglich gemacht.