
Dietrich online
Weiterlesen →
Mit Dietrich online werden bibliographische Angaben zu ca. 5. Mio im deutschen Sprachraum von 1897- 1944 erschienenen Zeitschriftenaufsätzen und Zeitungsartikeln
Mit Dietrich online werden bibliographische Angaben zu ca. 5. Mio im deutschen Sprachraum von 1897- 1944 erschienenen Zeitschriftenaufsätzen und Zeitungsartikeln

GAMS ist ein OAIS-konformes Repositorium zur Verwaltung, Publikation und Langzeitarchivierung digitaler Ressourcen aus allen geisteswissenschaftlichen Fächern.

Das Hidden Kosmos – Reconstructing Alexander von Humboldt’s »Kosmos-Lectures« widmete sich von 2014–16 der Ermittlung und Verzeichnung, Bild- und Volltext-Digitalisierung
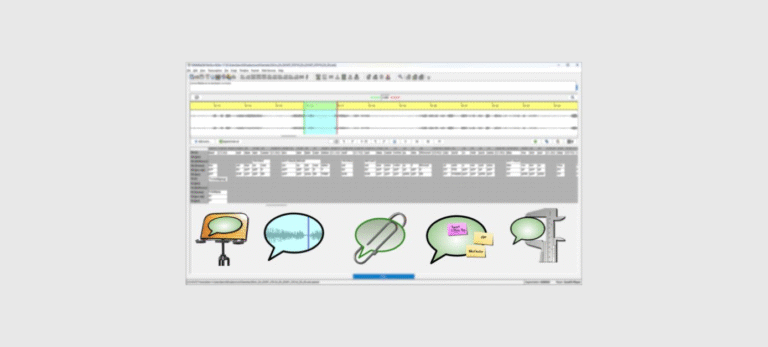
EXMARaLDA wurde ursprünglich (2000-2011) am SFB Mehrsprachigkeit der Universität Hamburg entwickelt. Die Entwicklung von FOLKER und OrthoNormal wurde über das

Das DARIAH-DE Repository ist eine zentrale Komponente der DARIAH-DE Forschungsdaten-Föderationsarchitektur, die verschiedene Dienste und Anwendungen aggregiert und so komfortabel nutzbar
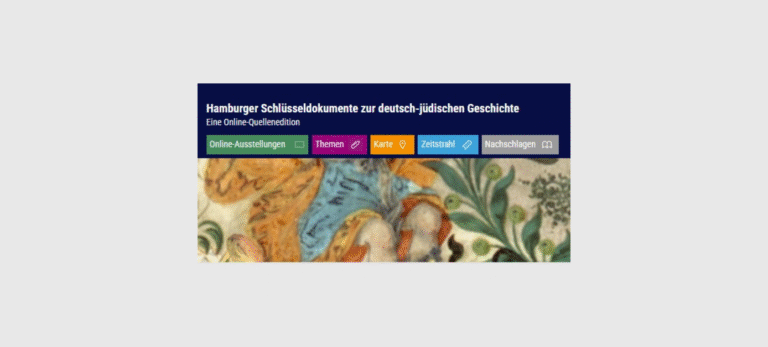
Die Edition „Hamburger Schlüsseldokumente zur deutsch-jüdischen Geschichte“ soll sowohl einem akademischen Publikum als auch der interessierten Öffentlichkeit einen niedrigschwelligen Zugang

Die Virtuelle Forschungsumgebung TextGrid ist optimiert für die digitale Erschließung geisteswissenschaftlicher Quellen und deren langfristige Archivierung in einem Web-Archiv, insbesondere von TEI-codierten Ressourcen

Das Forschungs- und Lehrkorpus Gesprochenes Deutsch (FOLK) wird seit 2008 am Leibniz-Institut für Deutsche Sprache aufgebaut. Das Korpus enthält Audio- und Videoaufnahmen von natürlichen Interaktionen aus unterschiedlichsten Bereichen des gesellschaftlichen Lebens (Arbeit, Freizeit, Bildung, öffentliches Leben, Dienstleistungen usw.) im deutschen Sprachraum.