
HZSK
Weiterlesen →
Das Hamburger Zentrum für Sprachkorpora berät und unterstützt bei der Erstellung und Nutzung digitaler Sprachkorpora in Forschung und Lehre: Es
Das Hamburger Zentrum für Sprachkorpora berät und unterstützt bei der Erstellung und Nutzung digitaler Sprachkorpora in Forschung und Lehre: Es

Das Forschungs- und Lehrkorpus Gesprochenes Deutsch (FOLK) wird seit 2008 am Leibniz-Institut für Deutsche Sprache aufgebaut. Das Korpus enthält Audio-
Das von der Deutschen Forschungsgemeinschaft geförderte Projekt Diccionario del Español Medieval electrónico (DEMel) hat zum Ziel, der Öffentlichkeit ein lemmatisiertes
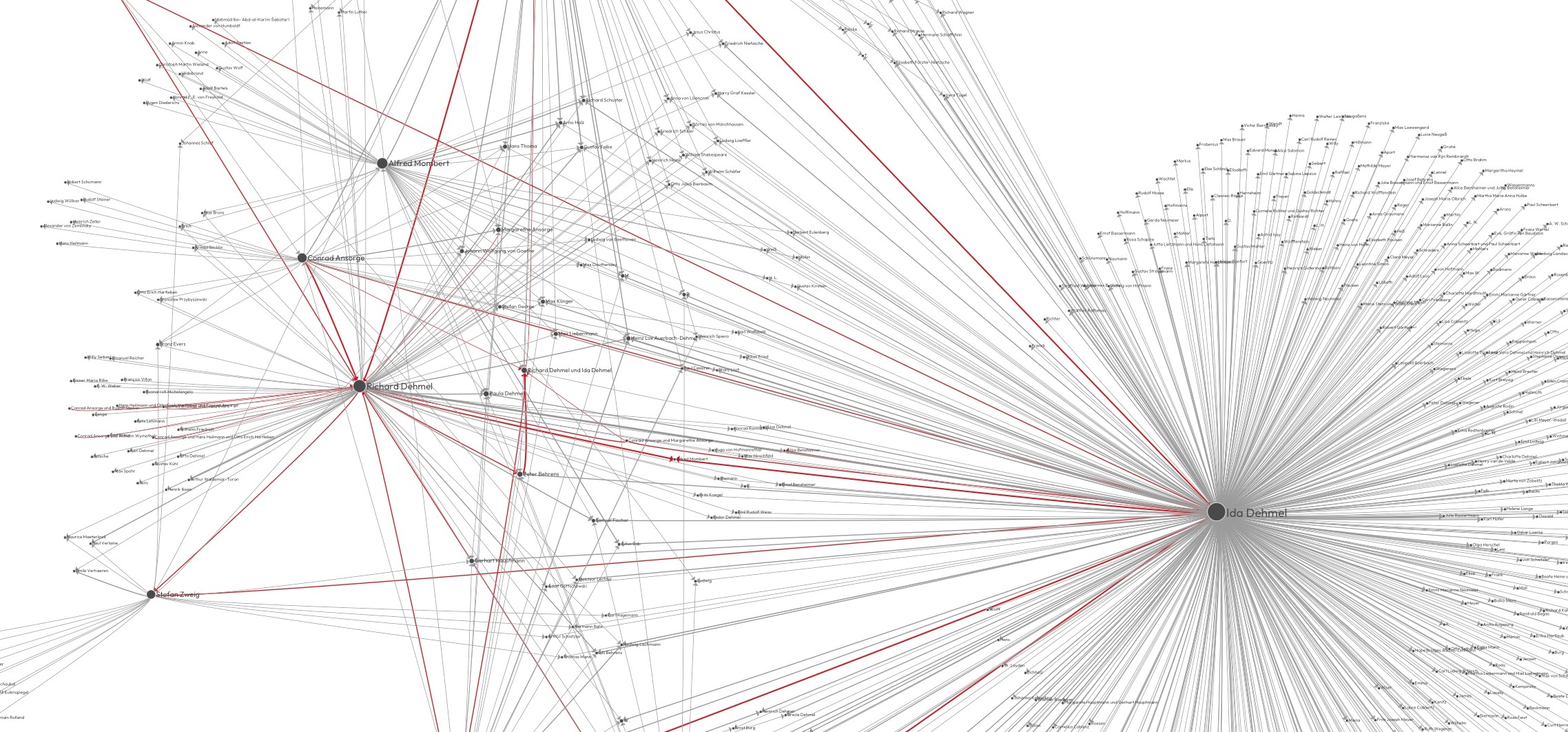
In Kooperation zwischen der Universität Hamburg und der Staats- und Universitätsbibliothek Hamburg werden die ca. 35.000 handschriftlichen Originalbriefe des Dehmel-Archivs
Das Hamburger Zentrum für Sprachkorpora berät und unterstützt bei der Erstellung und Nutzung digitaler Sprachkorpora in Forschung und Lehre: Es

is in die 1990er Jahre war es in der Filmwissenschaft ein Gemeinplatz, dass Frauen in den Anfangsjahren der Filmproduktion nur

Von 1958 bis 1973 lebte und arbeitete der anglo-amerikanische Dichter Wystan Hugh Auden (1907-1973) viele Monate im Jahr im niederösterreichischen

Das Hamburger Zentrum für Sprachkorpora berät und unterstützt bei der Erstellung und Nutzung digitaler Sprachkorpora in Forschung und Lehre: Es versteht sich als Kompetenzzentrum, das technische, methodische und organisatorische Expertise für die Arbeit mit Sprachkorpora aufbaut und bündelt.