
Dietrich online
Weiterlesen →
Mit Dietrich online werden bibliographische Angaben zu ca. 5. Mio im deutschen Sprachraum von 1897- 1944 erschienenen Zeitschriftenaufsätzen und Zeitungsartikeln
Mit Dietrich online werden bibliographische Angaben zu ca. 5. Mio im deutschen Sprachraum von 1897- 1944 erschienenen Zeitschriftenaufsätzen und Zeitungsartikeln

Das Akademienvorhaben hat die philologische Erschließung und kritische Edition antiker und byzantinischer Kommentare, Paraphrasen, Kompendien und Scholien zu den Schriften
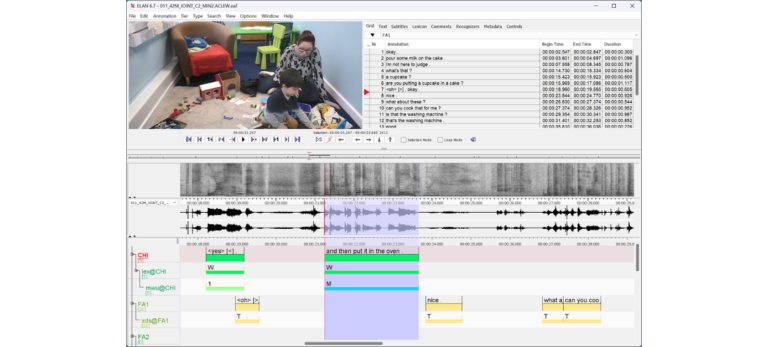
ELAN wird am Max-Planck-Institut für Psycholinguistik im Sprach-Archiv (TLA – The Language Archive) entwickelt. Es wird in der Programmiersprache Java
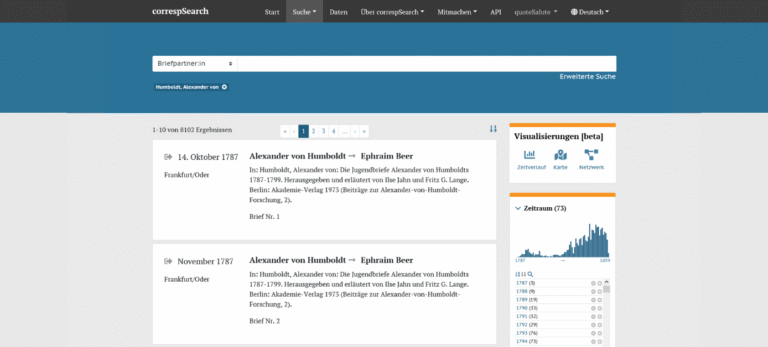
Der Webservice correspSearch wurde entwickelt um ein lange bestehendes Desiderat von Briefeditionen zu beheben: Die edierten Briefe editionsübergreifend durchsuchen zu

CLARIAH-DE ist ein Beitrag zur digitalen Forschungsinfrastruktur für die Geisteswissenschaften und benachbarte Disziplinen. Durch die Zusammenführung der Verbünde CLARIN-D und

ZenMEM ist ein dezidiert offener Verbund von Wissenschaftler*innen und darum bemüht, gemeinsam neue, digital gestützte Forschungsmöglichkeiten im Bereich der Kulturwissenschaften

Das Ziel der Bibliotheca legum ist es, einen Überblick über die handschriftliche Produktion weltlichen Rechts in der Karolingerzeit zu geben. Die Bibliotheca präsentiert Beschreibungen (nach TEI P5) aller Handschriften, die weltliche Rechtstexte (leges) enthalten sowie weitere kontextualisierende Materialien.

CLARIAH-DE ist ein Beitrag zur digitalen Forschungsinfrastruktur für die Geisteswissenschaften und benachbarte Disziplinen. Durch die Zusammenführung der Verbünde CLARIN-D und