
ediarum
Weiterlesen →
Die digitale Arbeitsumgebung ediarum ist eine aus mehreren Softwarekomponenten bestehende Lösung, die es Wissenschaftler*innen erlaubt, Transkriptionen von Manuskripten und Drucken
Die digitale Arbeitsumgebung ediarum ist eine aus mehreren Softwarekomponenten bestehende Lösung, die es Wissenschaftler*innen erlaubt, Transkriptionen von Manuskripten und Drucken

Das Institut für Dokumentologie und Editorik e.V. (IDE) ist ein internationaler Zusammenschluss von Wissenschaftlerinnen und Wissenschaftlern aus verschiedenen Disziplinen der

Die im aschkenasischen Europa und Norditalien verbreiteten Pinkasim – Protokollbücher jüdischer Gemeinden – sind zentrale Quellen zur Erforschung der jüdischen

Das DARIAH-DE Repository ist eine zentrale Komponente der DARIAH-DE Forschungsdaten-Föderationsarchitektur, die verschiedene Dienste und Anwendungen aggregiert und so komfortabel nutzbar

CLARIAH-DE ist ein Beitrag zur digitalen Forschungsinfrastruktur für die Geisteswissenschaften und benachbarte Disziplinen. Durch die Zusammenführung der Verbünde CLARIN-D und
Das Projekt erarbeitet eine Neuedition der fränkischen Herrschererlasse („Kapitularien”), die zu den zentralen Rechtsquellen des europäischen Mittelalters gehören. Zum einen

Von 1958 bis 1973 lebte und arbeitete der anglo-amerikanische Dichter Wystan Hugh Auden (1907-1973) viele Monate im Jahr im niederösterreichischen
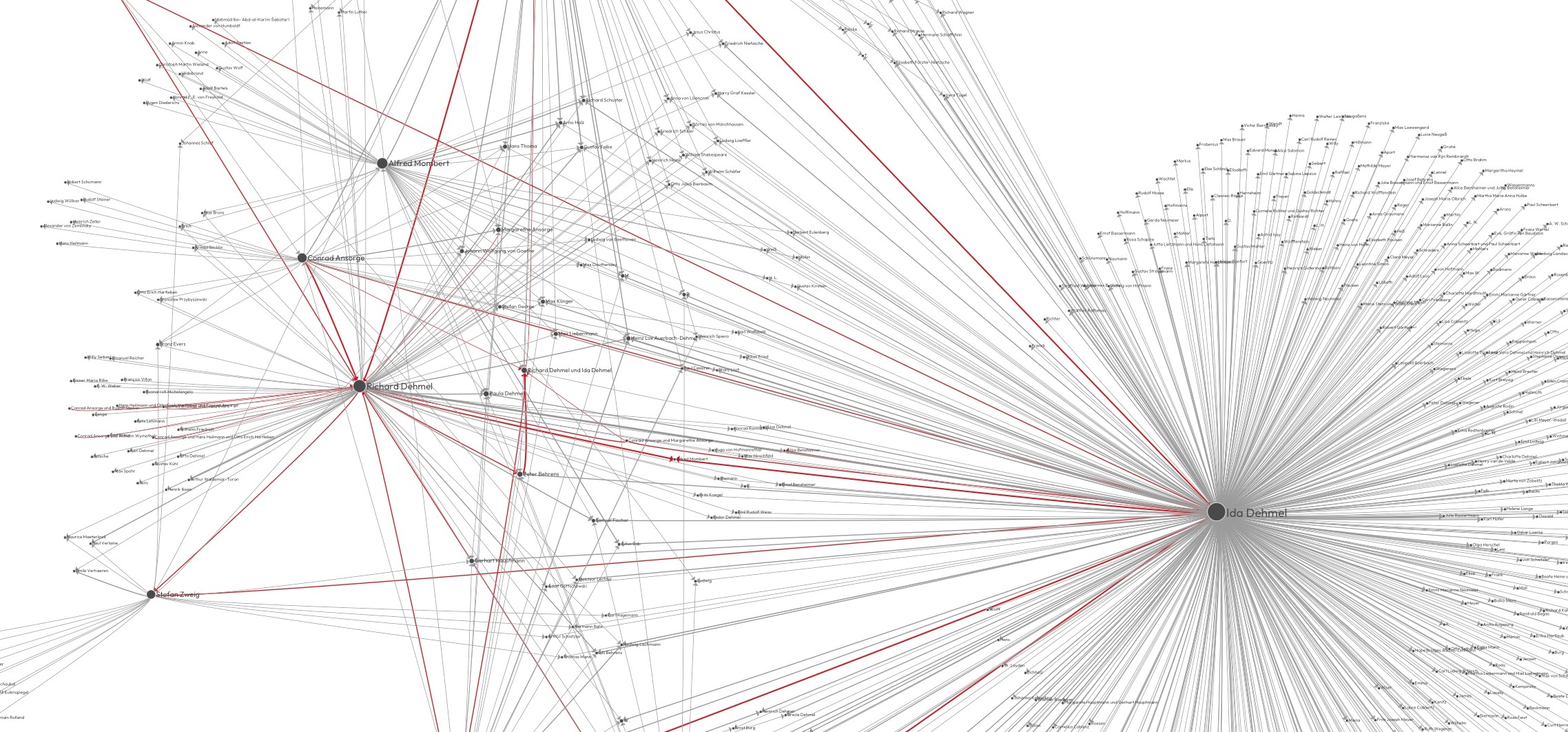
In Kooperation zwischen der Universität Hamburg und der Staats- und Universitätsbibliothek Hamburg werden die ca. 35.000 handschriftlichen Originalbriefe des Dehmel-Archivs