
TextGrid
Weiterlesen →
Die Virtuelle Forschungsumgebung TextGrid ist optimiert für die digitale Erschließung geisteswissenschaftlicher Quellen und deren langfristige Archivierung in einem Web-Archiv, insbesondere
Die Virtuelle Forschungsumgebung TextGrid ist optimiert für die digitale Erschließung geisteswissenschaftlicher Quellen und deren langfristige Archivierung in einem Web-Archiv, insbesondere

is in die 1990er Jahre war es in der Filmwissenschaft ein Gemeinplatz, dass Frauen in den Anfangsjahren der Filmproduktion nur

Das Hidden Kosmos – Reconstructing Alexander von Humboldt’s »Kosmos-Lectures« widmete sich von 2014–16 der Ermittlung und Verzeichnung, Bild- und Volltext-Digitalisierung

Das MultiHTR-Team setzt die Ergebnisse der ersten erfolgreichen Projektphase (01. Juni 2020 bis 31. Mai 2022) fort, um in der
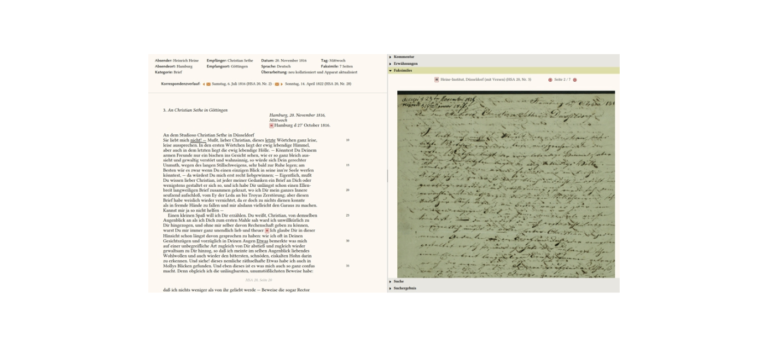
Das Heinrich-Heine-Portal schöpft aus den Arbeitsergebnissen mehrerer Forschergenerationen, indem es die beiden historisch-kritischen Heine-Gesamtausgaben, die unabhängig voneinander in der Bundesrepublik

DisKo steht für Diversitäts-Korpus und ist ein literaturwissenschaftliches Projekt mit Digital-Humanities-Komponente. Mit Methoden des maschinellen Lernens wollen wir einen Algorithmus

Das Projekt aggregiert Informationen zu digitalen Projekten und Konsortien, die sich im weitesten Sinne mit nicht-lateinischen Schriften beschäftigen. Die gesammelten Daten werden visualisiert und sollen Aussagen darüber treffen, was nötig ist, damit sich die Bedingungen für die Arbeit mit NLS im Bereich Digital Humanities bessern. Zusätzlich dient das Projekt als Knowledgebase für Forscher:innen, die sich einen Eindruck über den state of the field machen wollen. Das Projekt stellt alle Forschungsdaten, den Code und die Workflows im Open Access über GitHub zur Verfügung.

Das Hamburger Zentrum für Sprachkorpora berät und unterstützt bei der Erstellung und Nutzung digitaler Sprachkorpora in Forschung und Lehre: Es versteht sich als Kompetenzzentrum, das technische, methodische und organisatorische Expertise für die Arbeit mit Sprachkorpora aufbaut und bündelt.