Dehmel digital
Weiterlesen →
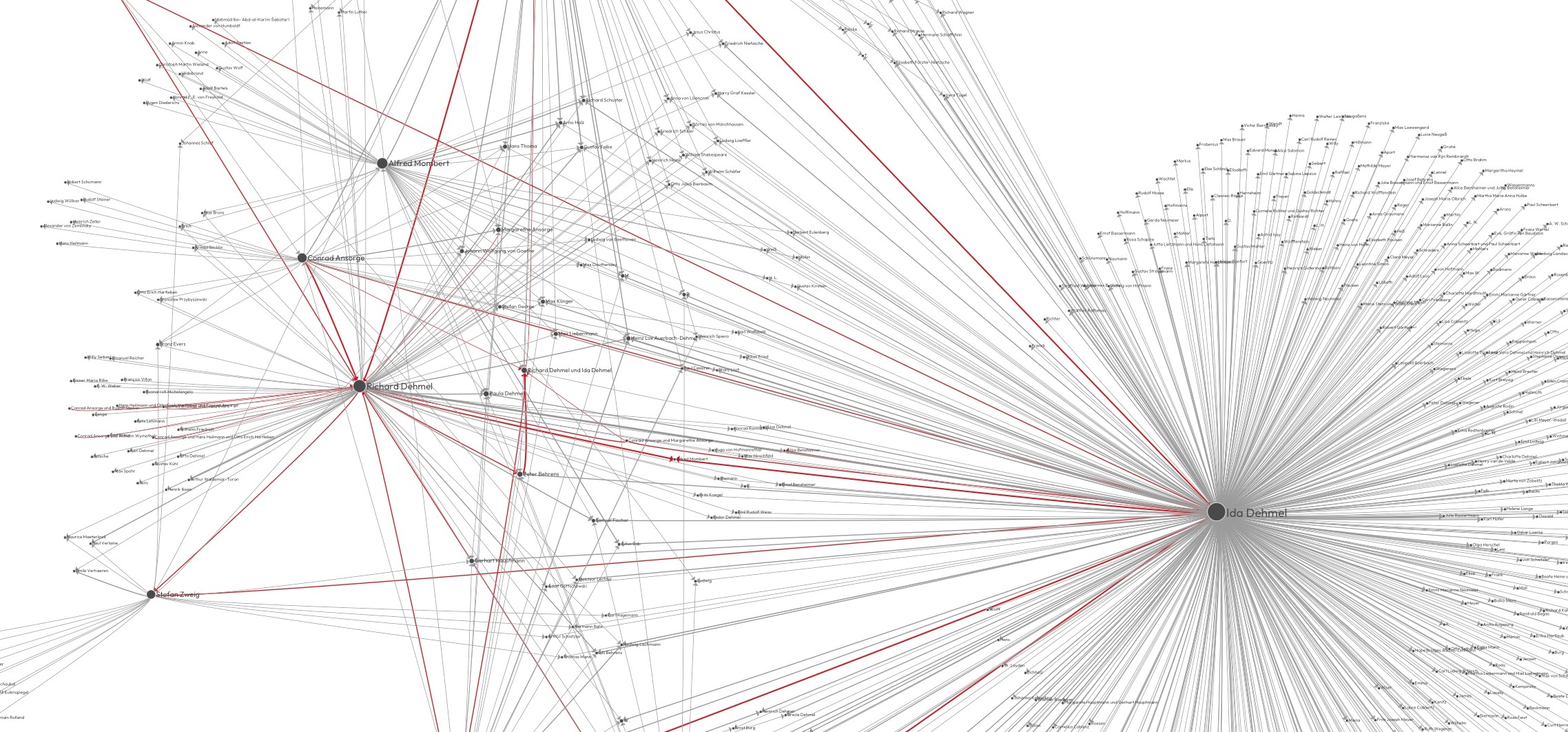
In Kooperation zwischen der Universität Hamburg und der Staats- und Universitätsbibliothek Hamburg werden die ca. 35.000 handschriftlichen Originalbriefe des Dehmel-Archivs
In Kooperation zwischen der Universität Hamburg und der Staats- und Universitätsbibliothek Hamburg werden die ca. 35.000 handschriftlichen Originalbriefe des Dehmel-Archivs

DisKo steht für Diversitäts-Korpus und ist ein literaturwissenschaftliches Projekt mit Digital-Humanities-Komponente. Mit Methoden des maschinellen Lernens wollen wir einen Algorithmus
Das von der Deutschen Forschungsgemeinschaft geförderte Projekt Diccionario del Español Medieval electrónico (DEMel) hat zum Ziel, der Öffentlichkeit ein lemmatisiertes

Das Zusammenwirken von über 1,200 Projektbeteiligten aus über 50 Ländern ermöglicht eine umfassende Darstellung der „Urkatastrophe des 20. Jahrhunderts“ in

Der Vergleich als methodisches und epistemologisches Paradigma ist in den Geisteswissenschaften tief verankert. Ob in der qualitativen oder quantitativen Forschung

GAMS ist ein OAIS-konformes Repositorium zur Verwaltung, Publikation und Langzeitarchivierung digitaler Ressourcen aus allen geisteswissenschaftlichen Fächern.

Das Hidden Kosmos – Reconstructing Alexander von Humboldt’s »Kosmos-Lectures« widmete sich von 2014–16 der Ermittlung und Verzeichnung, Bild- und Volltext-Digitalisierung sowie der Digitalen Edition sämtlicher überlieferter Nachschriften der Vorträge aus dem Kreis der Hörerinnen und Hörer, um somit die Erforschung dieses bedeutenden Ereignisses erstmals auf eine solide Quellengrundlage zu stellen.

Arthur Schnitzler gehört zu den bedeutendsten österreichischen Autoren und war ein produktiver und gut vernetzter Briefschreiber. Seine Korrespondenz wurde jedoch