ELAN
Weiterlesen →
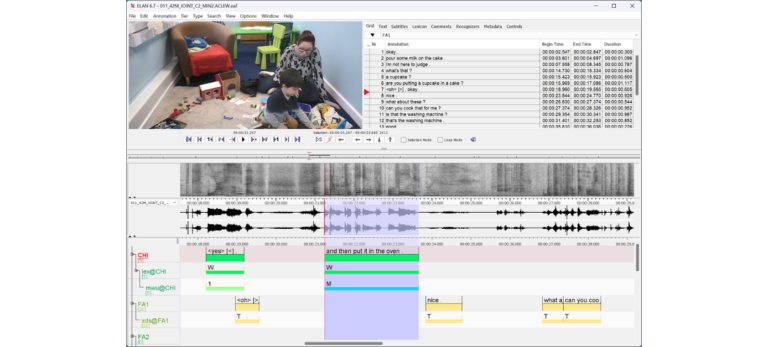
ELAN wird am Max-Planck-Institut für Psycholinguistik im Sprach-Archiv (TLA – The Language Archive) entwickelt. Es wird in der Programmiersprache Java
ELAN wird am Max-Planck-Institut für Psycholinguistik im Sprach-Archiv (TLA – The Language Archive) entwickelt. Es wird in der Programmiersprache Java

Die Virtuelle Forschungsumgebung TextGrid ist optimiert für die digitale Erschließung geisteswissenschaftlicher Quellen und deren langfristige Archivierung in einem Web-Archiv, insbesondere

Die Website „Der Holocaust in Ungarn und die Deportationen nach Norddeutschland“ präsentiert Ergebnisse aus dem transnationalen Projekt „Digitale Gedenk- und

DARIAH-DE (gefördert 2011-2019) unterstützt die mit digitalen Ressourcen und Methoden arbeitenden Geistes- und Kulturwissenschaftler/innen in Forschung und Lehre. Dazu baut

Digital edition of the economic-technological encyclopaedia by J. G. Krünitz, published in 242 volumes from 1773 to 1858.

Das von der NRW Akademie der Wissenschaften und der Künste sowie der Union der Deutschen Akademien finanzierte Langzeitprojekt an der

is in die 1990er Jahre war es in der Filmwissenschaft ein Gemeinplatz, dass Frauen in den Anfangsjahren der Filmproduktion nur
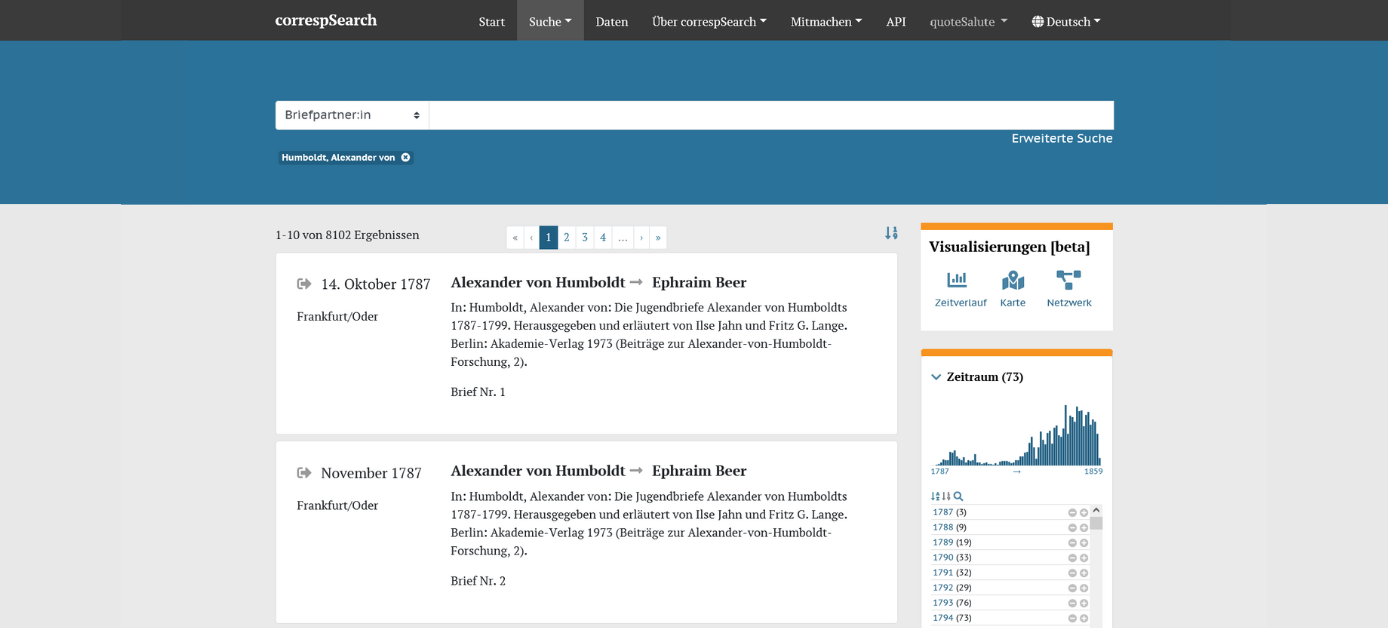
Der Webservice correspSearch wurde entwickelt um ein lange bestehendes Desiderat von Briefeditionen zu beheben: Die edierten Briefe editionsübergreifend durchsuchen zu