Œuvres de Frédéric le Grand
Weiterlesen →
Die digitale Ausgabe der Werke Friedrichs des Großen der Universitätsbibliothek Trier bietet eine XML-konforme und recherchierbare elektronische Volltextversion der von
Die digitale Ausgabe der Werke Friedrichs des Großen der Universitätsbibliothek Trier bietet eine XML-konforme und recherchierbare elektronische Volltextversion der von
Das Portal Revistas culturales 2.0 dient als virtuelle Forschungsumgebung für alle Interessenten, die sich mit historischen Zeitschriften aus dem spanischsprachigen

Das Institut für Dokumentologie und Editorik e.V. (IDE) ist ein internationaler Zusammenschluss von Wissenschaftlerinnen und Wissenschaftlern aus verschiedenen Disziplinen der
Das Fach ist BUA-finanziert und am Seminar für Semitistik und Arabistik angelegt. Es fokussiert sich auf die Analyse des status

Das vom Bundesministerium für Bildung und Forschung (BMBF) geförderte und am UCLAB der FH Potsdam angesiedelte Projekt Restaging Fashion (11.2020

In einem langfristigen Kooperationsprojekt von Österreichischer Nationalbibliothek und Deutschem Literaturarchiv Marbach werden alle bis 1990 entstandenen 75 Notizbücher in einer

The digital working environment ediarum is a solution consisting of several software components that allows scholars to edit transcriptions of manuscripts and prints in TEI-compliant XML, add commentaries and a critical apparatus as well as indexes and publish them on the web and in print.
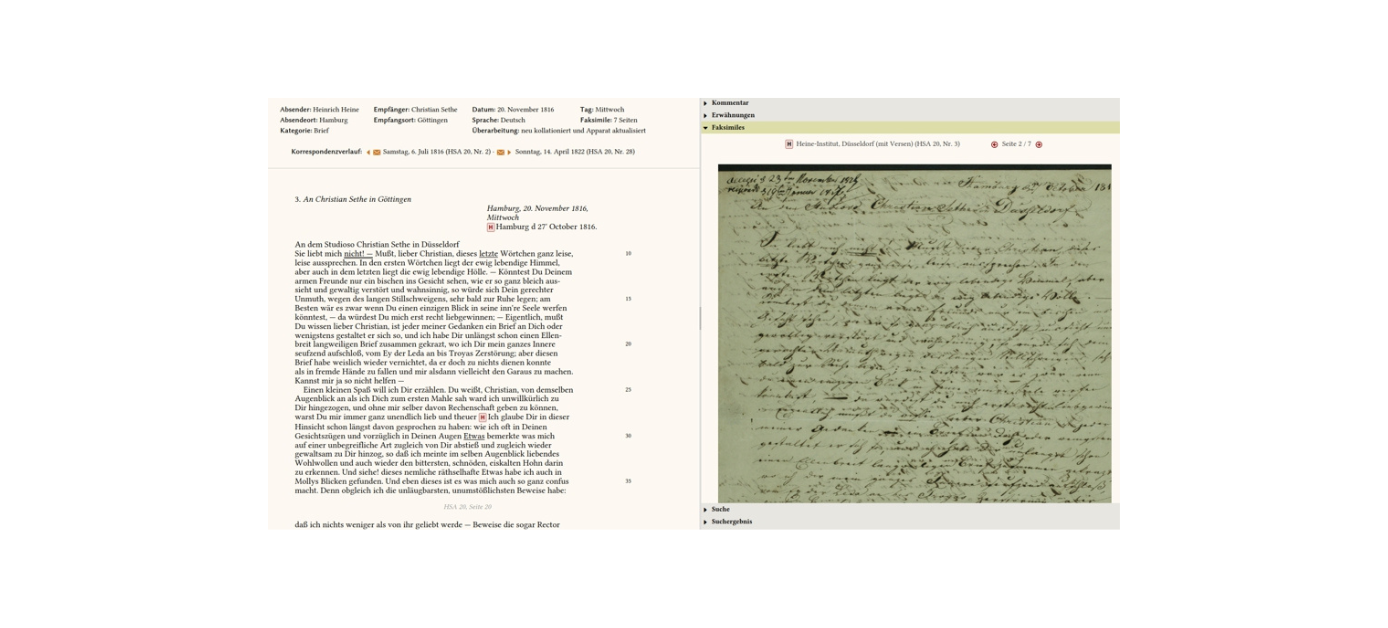
The Heinrich Heine Portal is based on the work of several generations of researchers by combining the two historical-critical complete editions of Heine, which were produced independently of each other in the Federal Republic of Germany and the German Democratic Republic, in one digital edition.