
CAGB
Weiterlesen →
Das Akademienvorhaben hat die philologische Erschließung und kritische Edition antiker und byzantinischer Kommentare, Paraphrasen, Kompendien und Scholien zu den Schriften
Das Akademienvorhaben hat die philologische Erschließung und kritische Edition antiker und byzantinischer Kommentare, Paraphrasen, Kompendien und Scholien zu den Schriften
Das Fach ist BUA-finanziert und am Seminar für Semitistik und Arabistik angelegt. Es fokussiert sich auf die Analyse des status

Das MultiHTR-Team setzt die Ergebnisse der ersten erfolgreichen Projektphase (01. Juni 2020 bis 31. Mai 2022) fort, um in der

Das Trierer Wörterbuchnetz bietet Zugriff auf mehr als 40 Wörterbücher und Nachschlagewerke, die entweder einzeln aufgerufen oder mittels einer übergreifenden
Das Fach ist BUA-finanziert und am Seminar für Semitistik und Arabistik angelegt. Es fokussiert sich auf die Analyse des status
Das Projekt erarbeitet eine Neuedition der fränkischen Herrschererlasse („Kapitularien”), die zu den zentralen Rechtsquellen des europäischen Mittelalters gehören. Zum einen
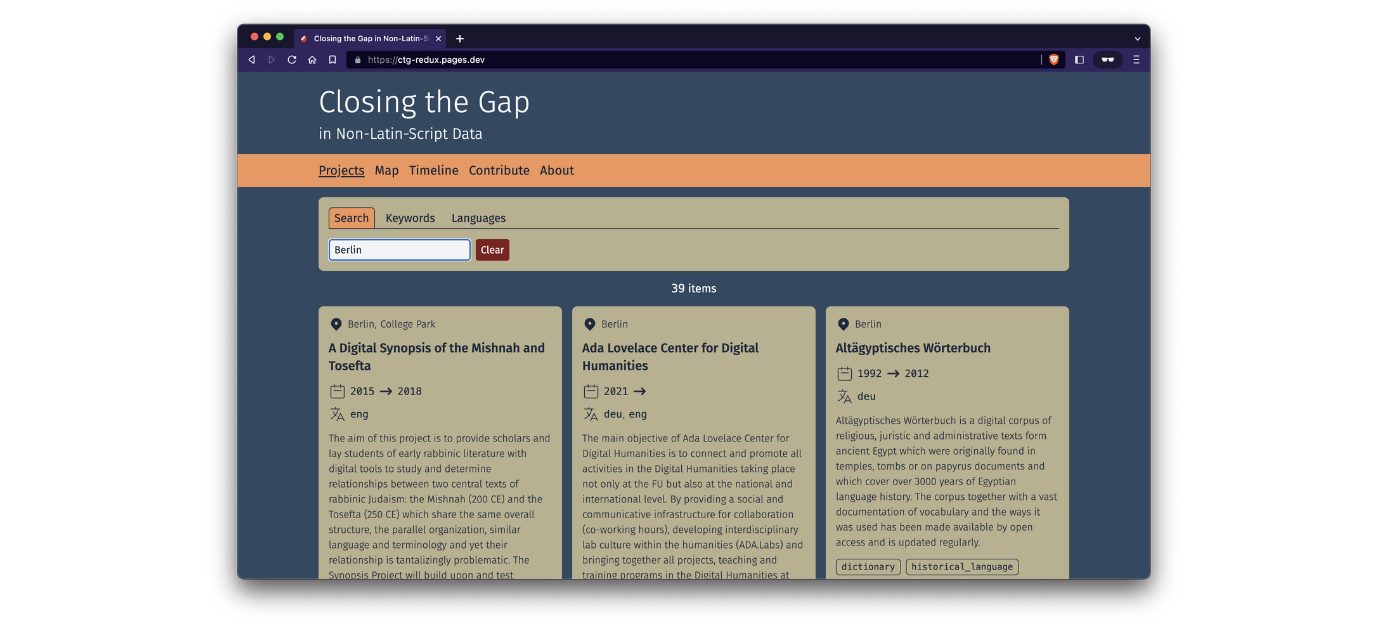
Das Fach ist BUA-finanziert und am Seminar für Semitistik und Arabistik angelegt. Es fokussiert sich auf die Analyse des status

Nachhaltiges Forschungsdatenmanagement ist zentral für künftige Forschungen! Dies zeigt etwa die Geschichte der Bonner Längsschnittstudie des Alterns. Fast zwanzig Jahre