
Institut für Dokumentologie und Editorik
Weiterlesen →
Das Institut für Dokumentologie und Editorik e.V. (IDE) ist ein internationaler Zusammenschluss von Wissenschaftlerinnen und Wissenschaftlern aus verschiedenen Disziplinen der
Das Institut für Dokumentologie und Editorik e.V. (IDE) ist ein internationaler Zusammenschluss von Wissenschaftlerinnen und Wissenschaftlern aus verschiedenen Disziplinen der
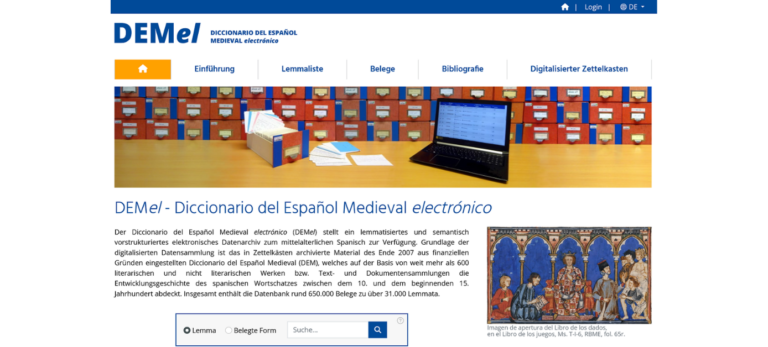
Das von der Deutschen Forschungsgemeinschaft geförderte Projekt Diccionario del Español Medieval electrónico (DEMel) hat zum Ziel, der Öffentlichkeit ein lemmatisiertes
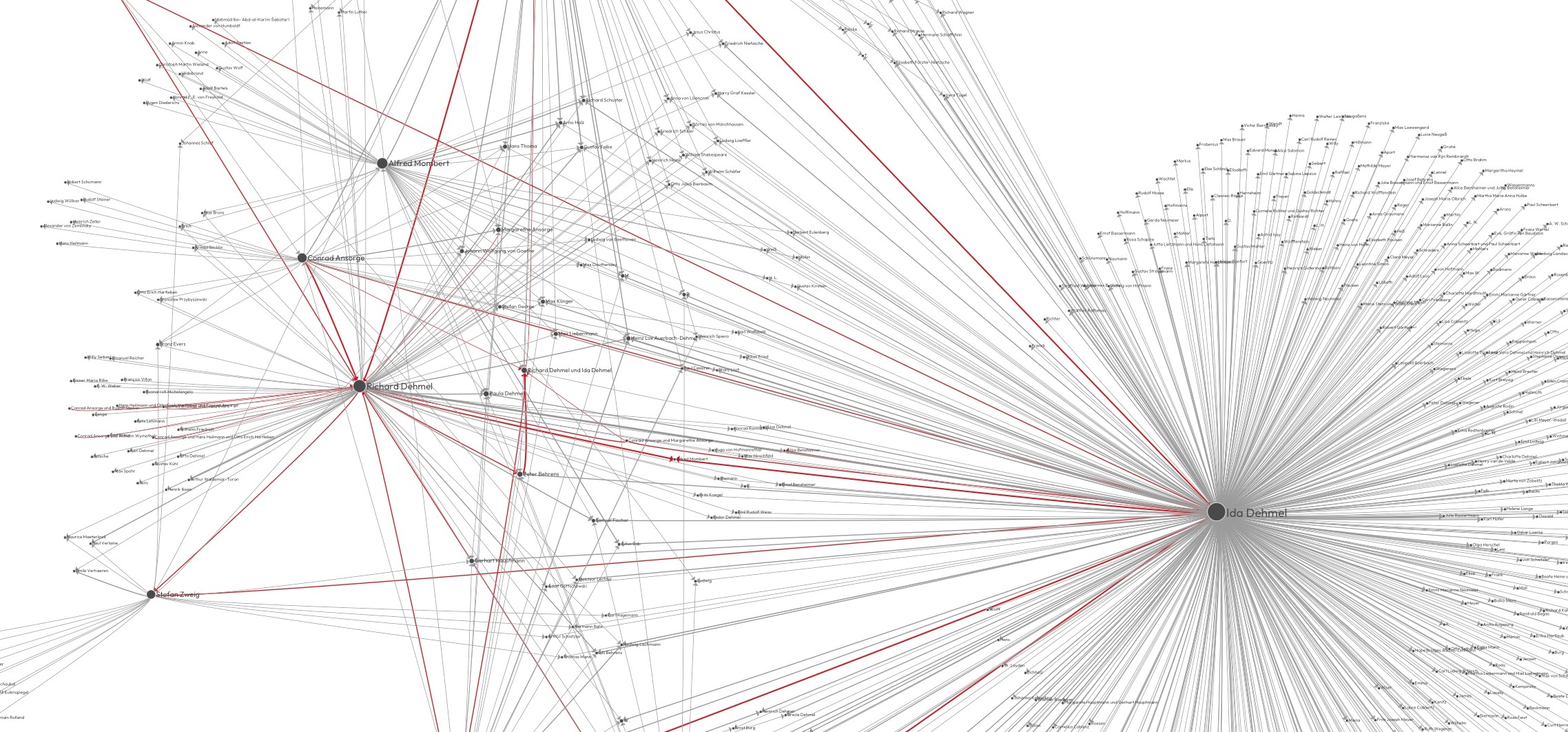
In Kooperation zwischen der Universität Hamburg und der Staats- und Universitätsbibliothek Hamburg werden die ca. 35.000 handschriftlichen Originalbriefe des Dehmel-Archivs

Die Virtuelle Forschungsumgebung TextGrid ist optimiert für die digitale Erschließung geisteswissenschaftlicher Quellen und deren langfristige Archivierung in einem Web-Archiv, insbesondere

ZenMEM ist ein dezidiert offener Verbund von Wissenschaftler*innen und darum bemüht, gemeinsam neue, digital gestützte Forschungsmöglichkeiten im Bereich der Kulturwissenschaften

Die im aschkenasischen Europa und Norditalien verbreiteten Pinkasim – Protokollbücher jüdischer Gemeinden – sind zentrale Quellen zur Erforschung der jüdischen
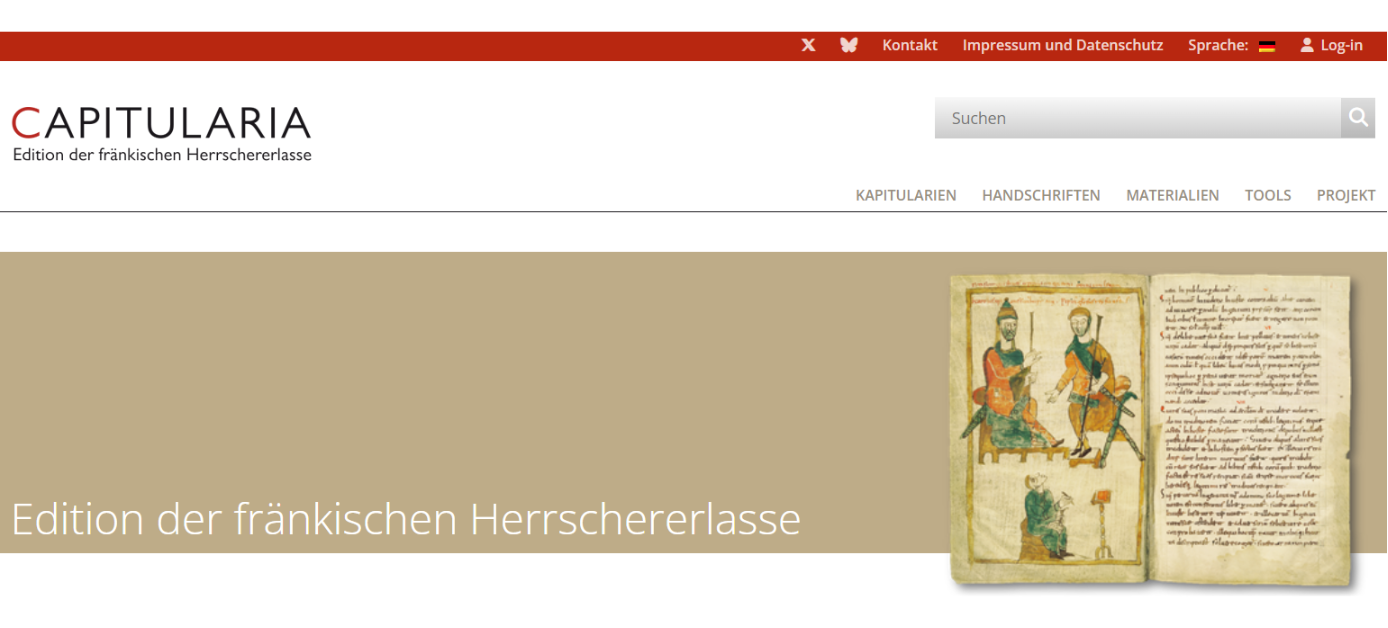
Das Projekt erarbeitet eine Neuedition der fränkischen Herrschererlasse („Kapitularien”), die zu den zentralen Rechtsquellen des europäischen Mittelalters gehören. Zum einen werden die Herrschererlasse als Einzelstücke kritisch ediert und in ihrer rekonstruierten Form mit Übersetzung in Buchform publiziert; zum anderen die für die Wirkungs- und Rezeptionsgeschichte zentralen Sammlungen erschlossen und in einer digitalen Edition für die Forschung zugänglich gemacht.
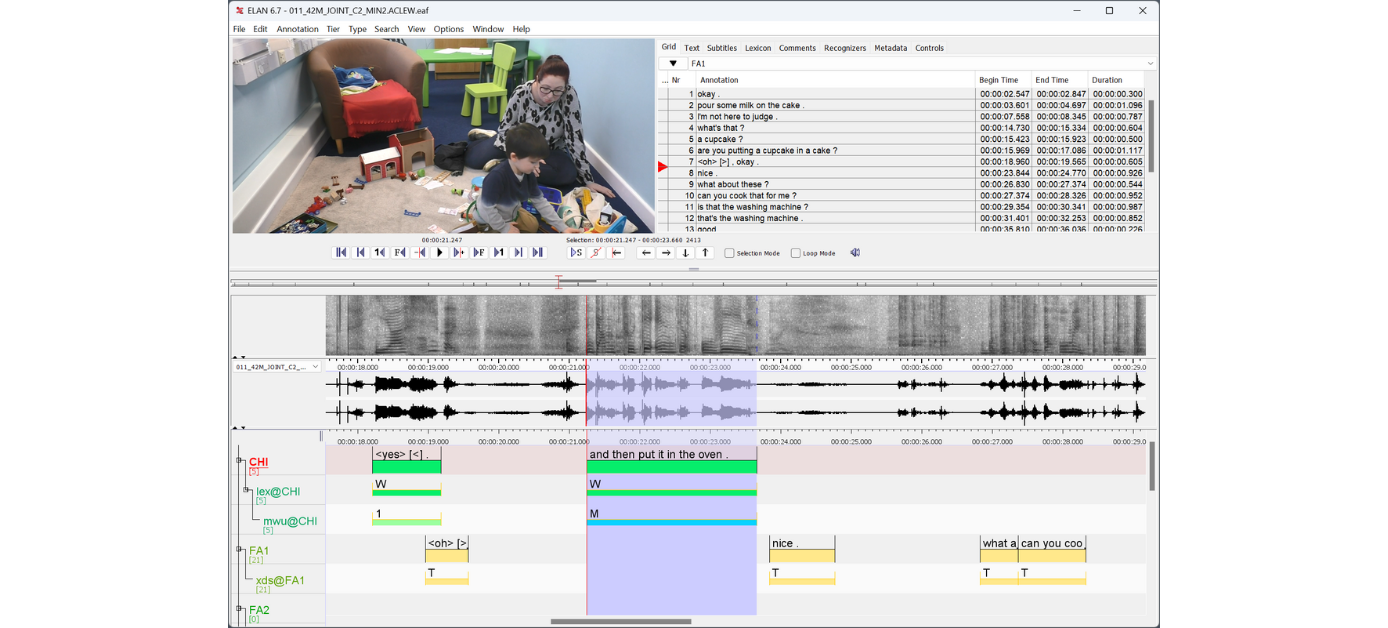
ELAN wird am Max-Planck-Institut für Psycholinguistik im Sprach-Archiv (TLA – The Language Archive) entwickelt. Es wird in der Programmiersprache Java geschrieben, die Quellen sind erhältlich für non-kommerzielle und kommerzielle Zwecken.