
DARIAH-DE Repository
Weiterlesen →
Das DARIAH-DE Repository ist eine zentrale Komponente der DARIAH-DE Forschungsdaten-Föderationsarchitektur, die verschiedene Dienste und Anwendungen aggregiert und so komfortabel nutzbar
Das DARIAH-DE Repository ist eine zentrale Komponente der DARIAH-DE Forschungsdaten-Föderationsarchitektur, die verschiedene Dienste und Anwendungen aggregiert und so komfortabel nutzbar

Der Vergleich als methodisches und epistemologisches Paradigma ist in den Geisteswissenschaften tief verankert. Ob in der qualitativen oder quantitativen Forschung

Im Zentrum steht die Erforschung digitaler, datenintensiver Medien, die sich auf breiter Front als kooperative Werkzeuge, Plattformen und Infrastrukturen herausgestellt

Das Trierer Wörterbuchnetz bietet Zugriff auf mehr als 40 Wörterbücher und Nachschlagewerke, die entweder einzeln aufgerufen oder mittels einer übergreifenden

Das Projekt aggregiert Informationen zu digitalen Projekten und Konsortien, die sich im weitesten Sinne mit nicht-lateinischen Schriften beschäftigen. Die gesammelten

Das Hamburger Zentrum für Sprachkorpora berät und unterstützt bei der Erstellung und Nutzung digitaler Sprachkorpora in Forschung und Lehre: Es
Die digitale Ausgabe der Werke Friedrichs des Großen der Universitätsbibliothek Trier bietet eine XML-konforme und recherchierbare elektronische Volltextversion der von Johann David Erdmann Preuß zwischen 1846 und 1856 herausgegeben Werkausgabe sowie der von Reinhold Koser begründeten Ausgabe der Politischen Correspondenz Friedrichs des Großen der Jahre 1740-1782.
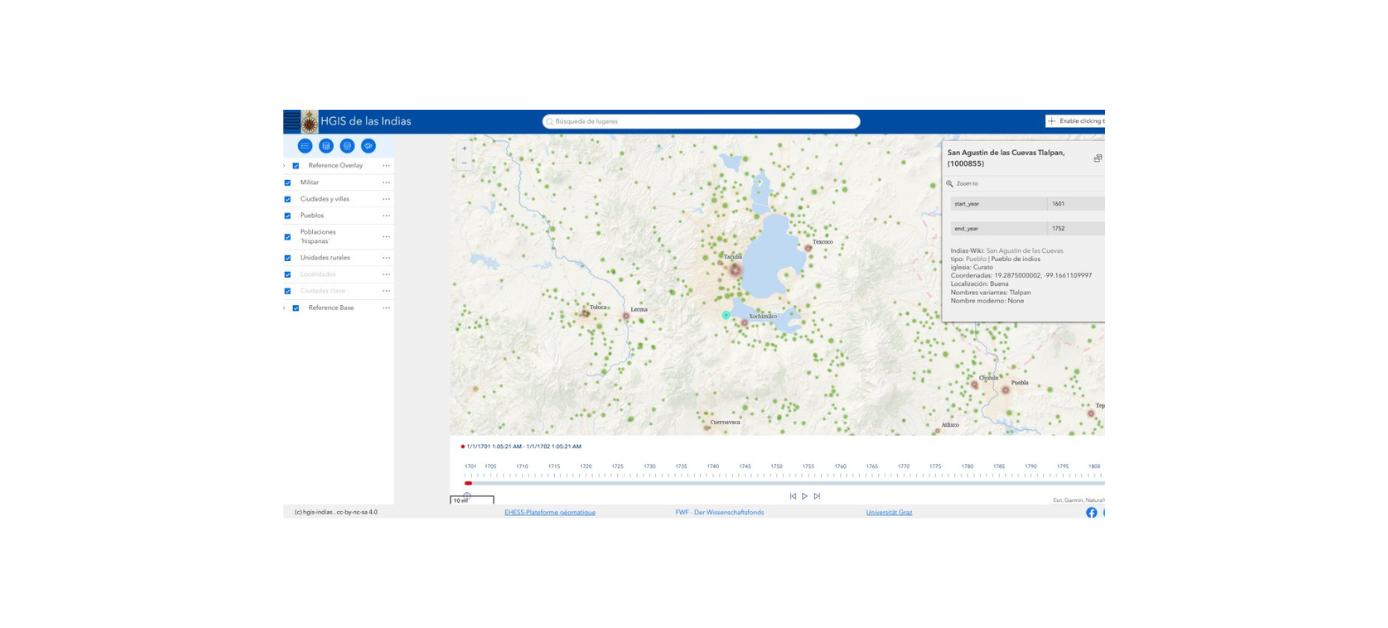
HGIS de las Indias ist eine historisch-geographische Datenbank zum Spanisch-Amerika der ausgehenden Kolonialzeit.