
DARIAH-DE
Weiterlesen →
DARIAH-DE (gefördert 2011-2019) unterstützt die mit digitalen Ressourcen und Methoden arbeitenden Geistes- und Kulturwissenschaftler/innen in Forschung und Lehre. Dazu baut
DARIAH-DE (gefördert 2011-2019) unterstützt die mit digitalen Ressourcen und Methoden arbeitenden Geistes- und Kulturwissenschaftler/innen in Forschung und Lehre. Dazu baut

Annotieren, Analysieren, Interpretieren und Visualisieren: In CATMA können Textwissenschaftler:innen so arbeiten, wie es ihren Fragestellungen am besten entspricht: qualitativ oder

Der DARIAH-DE Geo-Browser ermöglicht eine vergleichende Visualisierung mehrerer Anfragen und unterstützt die Darstellung von Daten und deren Visualisierung in einer
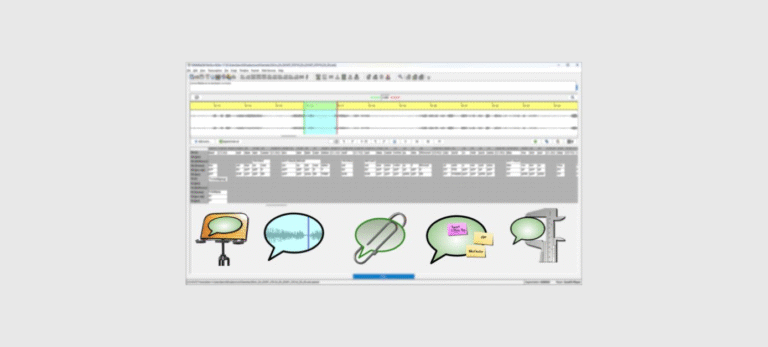
EXMARaLDA wurde ursprünglich (2000-2011) am SFB Mehrsprachigkeit der Universität Hamburg entwickelt. Die Entwicklung von FOLKER und OrthoNormal wurde über das

Im Zentrum steht die Erforschung digitaler, datenintensiver Medien, die sich auf breiter Front als kooperative Werkzeuge, Plattformen und Infrastrukturen herausgestellt

Die Website schafft einen schnellen und unkomplizierten Zugang zu den Werkmaterialien des österreichischen Literaturnobelpreisträgers Peter Handke.
Das Institut für Dokumentologie und Editorik e.V. (IDE) ist ein internationaler Zusammenschluss von Wissenschaftlerinnen und Wissenschaftlern aus verschiedenen Disziplinen der Geisteswissenschaften, die sich den Digital Humanities zugehörig fühlen.

Das Akademienvorhaben hat die philologische Erschließung und kritische Edition antiker und byzantinischer Kommentare, Paraphrasen, Kompendien und Scholien zu den Schriften des Aristoteles zum Ziel.